目录
1.数据库安装 1
2. 建库 4
3.创建监听 10
4.工具介绍 13
5.创建用户 16
6.常用数据类型 18
7.建表 19
8.sqlDeveloper数据库复制 21
9.简单查询 24
10.常用函数 28
11.联合查询 39
12.视图 40
13.decode函数 43
14.分页 49
15.主键 52
16.序列 54
17.数据字典 55
18.索引 57
19.PL/SQL编程 61
19.1 基础结构 61
19.2 helloworld 62
19.3变量的定义和赋值 62
19.4变量的基础类型 63
19.5动态赋值 64
19.6异常处理 65
19.7变量的复杂类型 66
1)%type 66
2) %rowtype 67
1.数据库安装版本: 9i 10g 11g xe
数据库: mysql sqlserver oralce db2…..
安装时注意:管理员权限
安装好之后,
1)开始菜单有功能键
2)服务中能看到
计算机—》右键,管理—》服务和应用程序—》服务—》
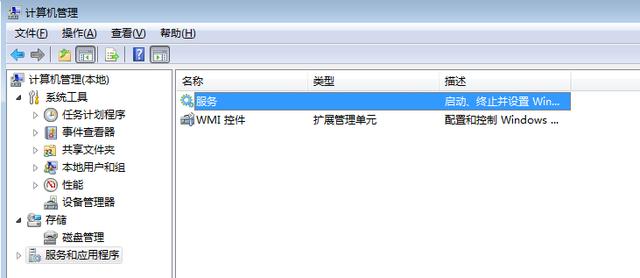
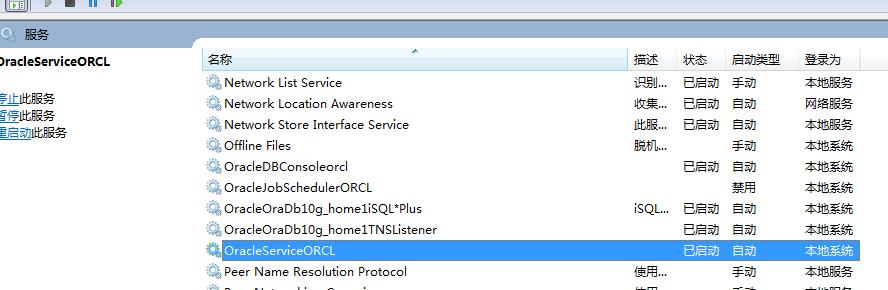
启动类型可以修改为手动
选中程序—》右键,属性, 修改启动类型为手动,在需要的时候启动数据库
oracle中每个库都有自己的进程,相互独立
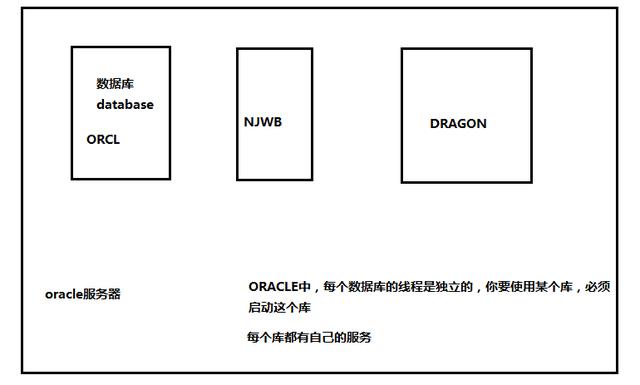
数据库: 数据存储仓库,将数据以文件形式,存储在磁盘上
oracle卸载: 有部分注册表数据,需要手动删除。建议卸载之前,度娘一下攻略。
2. 建库图形化工具
开始菜单

建库:

数据库名 和 sid保持一致

口令,统一使用 admin

可以设置字符集编码

oralce中主要的文件类型
控制文件: .ctl 数据库配置信息
数据文件: .dbf --》存储的数据的文件
日志文件: .log
创建成功之后,口令管理,可以看到这个库默认的所有用户

解锁scott用户,scott用户是oracle给的样例
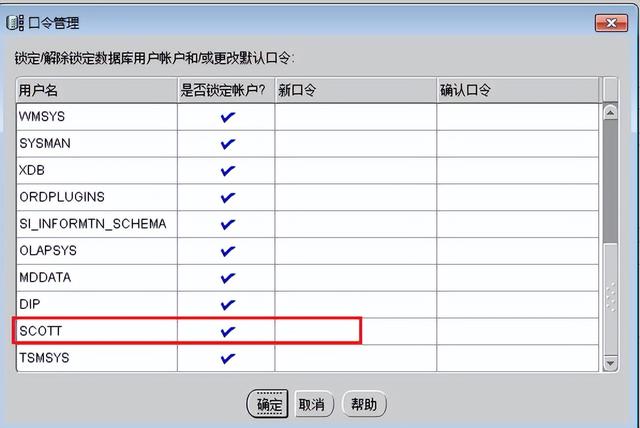
解锁,密码使用admin ,原始密码tiger

建库成功之后:

连接数据库:
先使用oracle自带的连接工具 sqlPlus


连接成功
3.创建监听可能在连接时会遇到的问题: ORA-12541 无监听程序
ORA-12541 : oracle的错误码

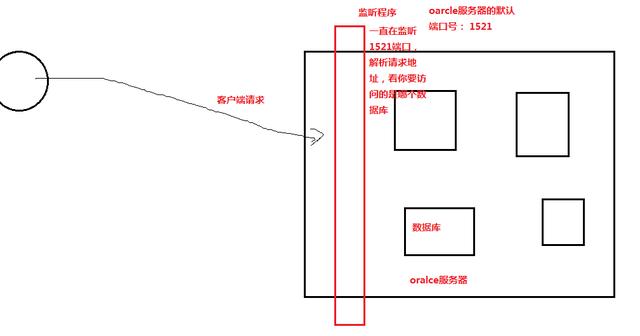
监听怎么创建?
网络配置助手

监听配置完成之后,在服务中有监听服务
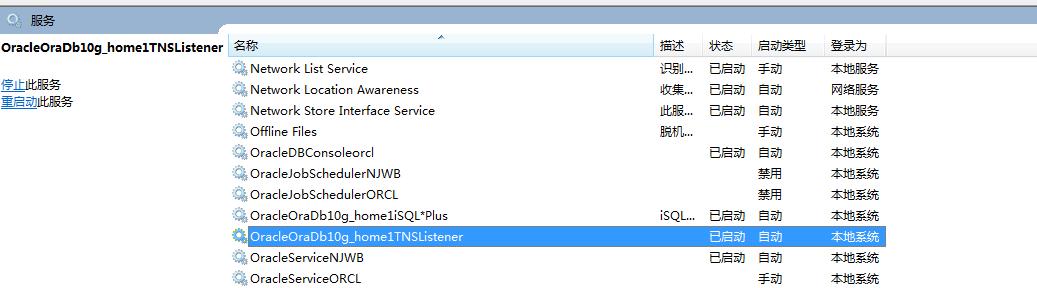
监听配置好之后,重新连接数据库:

连接数据库:

连接方式:
1)sqlPlus
2)plsql
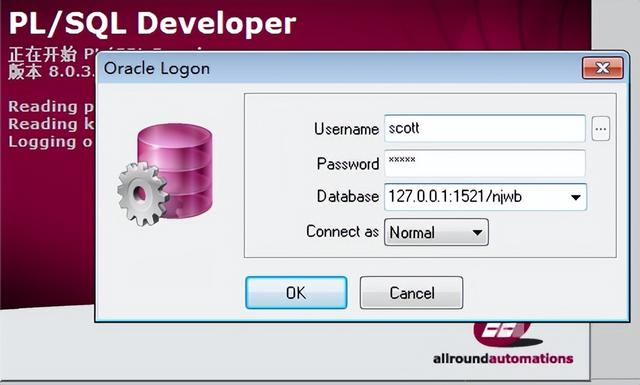
Database: ip:port/sid
配置数据库选项(Database的下拉菜单)
帮助—》支持信息


3)sqlDeveloper
linux下

新建连接:

建立成功:


1.创建表空间
使用system/sys登录

2.创建用户

3.登录

没有权限
4.赋权限

单独权限太多,赋角色给用户,oracle中,权限是按角色分组的

字符型:
varchar
varchar2
nvarchar2
char
以上四种字符型的,分成2类
char: 定长,比如char(10),如果存储的是“a”,那么占用长度是10,不足,用空格补齐
varchar类型:变长,长度会根据具体存储的数据长度,来动态分配存储空间。
1.相同之处: 都是字符,都是变长,长度:最大4000.
2.不同之处:varchar2对于所有的字符都是2个长度存储,varchar中文2个长度,英文1个长度。nvarchar2:对中文支持最好的!!存储,也是使用2(还是3)个长度存储,使用的Unicode编码方式存储。
推荐使用nvarchar2
blob,clob 大文本存储(比如,长度超过4000的)
数字型
int float double….
开发中,常用类型number
1) number(11)
数字类型,整数,最大长度11位
2) number(10,2)
数字类型,整数位最大长度为8位,小数位最多2位。
时间类型
date, 带时分秒
7.建表create table table_name(
column_name type(length),
…..
)
需求:新建学生表 t_student ,列, t_id, t_stu_name, t_sex, t_create_time
t_id为主键
命名规则:
数据库中,oracle是不区分大小写的,所以,单词之间只用下划线分隔。
表名,一般使用t_ 打头

添加主键

主键添加方式,或者是命令

或者是:

对表数据做更新操作(update,delete,insert),一定要手动提交事务!!!

提交事务两种方式
点击提交按钮,或者是执行commit命令。
plsql中提交按钮
1.

2.

3.

可以默认全部切换(工作中,需要全部切换),也可以只复制表
4.点击“更多”
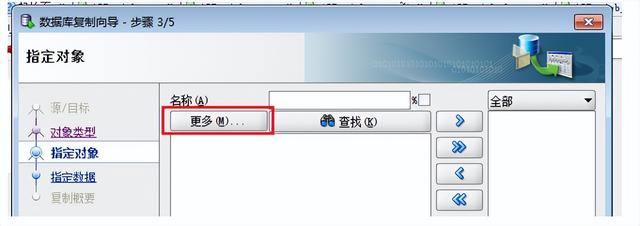
5.选中需要复制的表

效果:

6.下一步—》下一步—》。。。。--》完成
7.检查dragon用户中的表
刷新dragon用户的表

注意和mysql数据库中不一样的使用方式
- 需求1:查询年薪

- 需求2:查询年薪 津贴年终奖

有null值参与计算的结果==》为null
判断值是否为null,如果为null,则给0参与计算
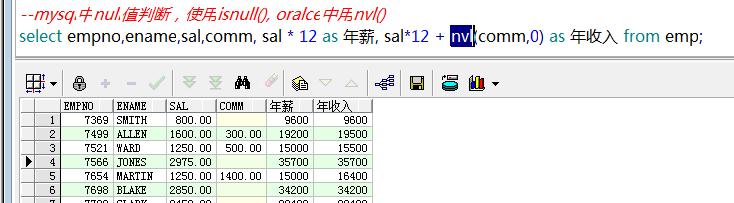
nvl(值, 替换值)
如果值为null,那么使用替换值代替
- 需求3:查询当前时间
查询入职时间在1985年1月1号之后的

入职时间比较
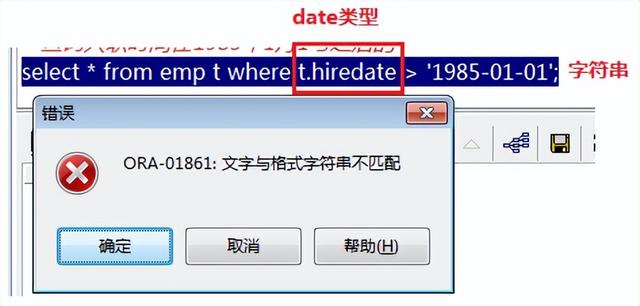
出错,比较符 “>”两边的类型不匹配
1)两边都是字符串

2)两边都是date

- 需求4: 将年薪使用千位分隔符表示
$10,190,111,000 ——》从数据类型上来说,字符串(varchar)
使用 to_char(值,格式)

- 需求5: 查询员工编码和姓名, 效果为: 7789_jones,7789’jones

在oracle中,是运算符,不是字符串连接符
字符串连接符: ||

- 需求6: 查询员工表中的部门,去重

- 需求7: 查询姓名中有M的;查询姓名中第二个字母为M的;查询姓名中含有%的

单行函数: 处理单条数据,比如substr()…
多行函数:处理多条数据得到结果, 比如avg(), max(),sum()
plsql中,函数联想:

需求1: 查询员工名称的第二个字母含有’a’或’A’

需求2:查询员工姓名,从第二个字符开始截取,截取3位


需求3:查询平均工资,采用四舍五入 ,保留4位有效数字
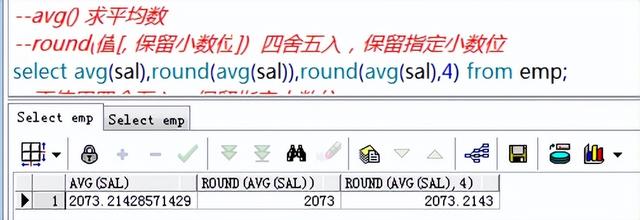


需求4:取余
mod(被除数,除数)

需求5:计算每个部门的平均薪资
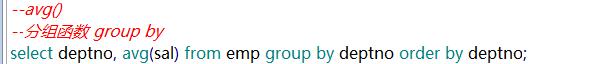
分组函数一定是配合多行函数使用
使用分组函数,那么查询结果集,除了使用函数的列,其他的列都必须在分组函数中

sql语句中关键字位置
select …..
from …..
inner join…
left join…
right join….
where …….
group by …..
having…
order by …..
需求6:查找所有员工中工资最高的员工信息

如果薪资为5000的用户有两个呢?
--查薪资为5000的用户信息
select * from emp where sal = 5000;
5000怎么来???
select max(sal) from emp;

需求7:查找所有员工中工资最低的员工信息

需求8:统计工资大于2000的员工数量
count()



需求9:统计每个部门的总薪资
求和 sum()
分组 group by

需求10:查询部门平均工资大于2000的部门信息



需求11:查询工资在平均工资之上的员工

需求12:查询职位是经理的员工


查询员工及其经理人的姓名
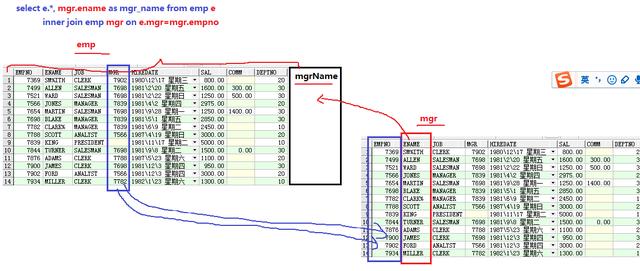

需求13:求出每个部门中工资最高的员工信息

需求14:求出每个部门平均工资的等级
有薪资的部门

展示所有的部门

需求15:求出员工及其经理人,根据部门、薪资排序

需求16: 求部门平均的薪资等级

需求17: 平均薪资最高的部门编号,名称与薪资等级

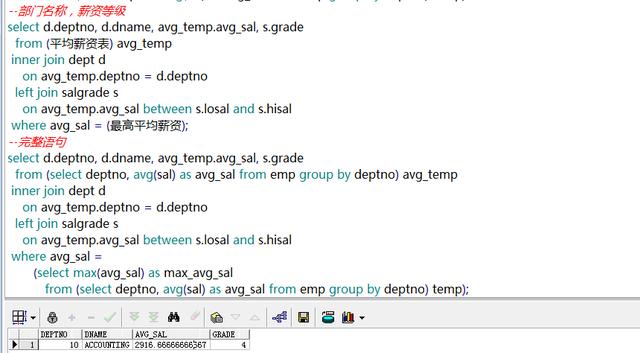
需求18: 查询部门平均薪资等级最低的此部门的所有员工,以及薪资在1000以下的员工
--查平均薪资等级 最低的部门编号
--平均薪资等级
--最低等级
--部门编号 where 平均薪资等级=最低等级


select * from emp where deptno in(等级最低编号) or sal < 1000
需求19: 员工表新增字段,状态,1:在职,2:离职,3:停薪留职。
查询员工信息,状态字段显示对应中文
11.联合查询union
union all


union

union all
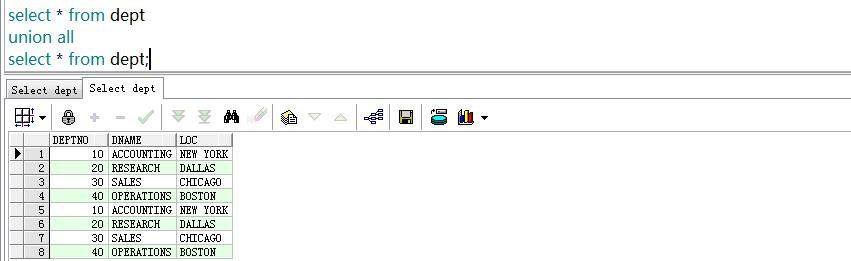
可以认为就是一个表,这个表又不是物理存在的。
将 查询语句的结果,作为一个临时表,并且给它个名字
语法:

使用:
和表的使用一样

--查询部门平均薪资等级最低的此部门的所有员工


作用
1.简化sql语句
2.一般用于平台之间的数据交互,主要提供视图给对方,保护数据
两个平台共享数据库的时候,
B平台 到A平台的数据库中捞数据,用权限来控制,只能捞我给定的视图
其他数据不可见。对数据有个保护的作用
比如: dragon用户中视图v_student可以给scott访问
1)登录dragon用户
2)使用dragon用户给scott用户赋权限

scott用户可以查询到dragon用户的v_student视图

视图可以修改么???
视图可以修改,但是不能违背基础表的规则,约束,视图的修改会同步到基础表
但是!!!!!一般不会去修改视图!
13.decode函数需求19: 员工表新增字段,状态,1:在职,2:离职,3:停薪留职。
查询员工信息,状态字段显示对应中文

纵表变横表
需求:
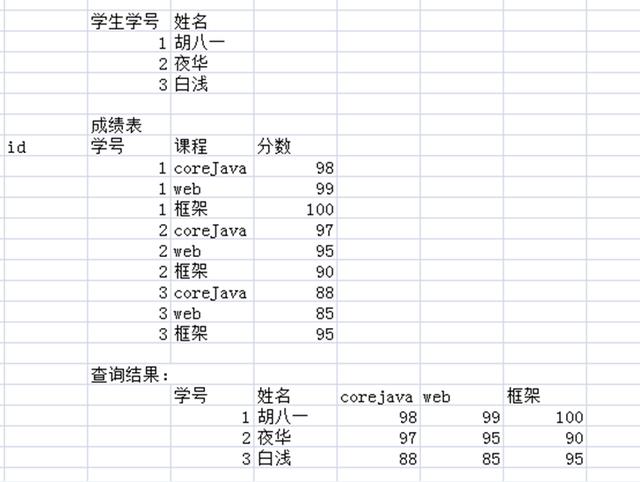
表设计:


sql语句步骤


3.数据填充




课后练习:

mysql 使用 limit startIndex,size
oracle 伪列 rownum
rownum就是一个序列号,

使用伪列的问题:

正确使用方式:

使用伪列分页,每页显示3条数据
第一页: 伪列 between 1 and 3
第二页: 伪列 between 4 and 6


排序:

使用排序的时候,一定要固定顺序
一般来说,先根据指定的列排序,最后,根据主键排序

主键是怎么定义的?
自增长序列作为主键
整数类型:
1)自增长序列, 1,2,3,4.。。。
2)自定义,比如deptno, 10,20,30…
字符类型:
1)有意义
手机号码
身份证号
。。。。。。
2)无意义
一般使用uuid 或者是guid(企业中使用比较多,主键为varchar2(32))
就是一个字符串
mysql中

oracle sys_guid()

每次调用生成不会重复的字符串。
自增长?
mysql中建表,定义主键使用自增长
oracle中没有
oracle中使用序列
16.序列1,2,3,4.。。。。。。。。。
要使用一个序列,肯定要先创建
语法:
序列名称使用seq_ 打头
create sequence 序列名;
create sequence seq_student;

序列使用:



序列和表有关系吗???
逻辑上,是有关系,一般来说,序列和表是一 一对应的关系
但是从本质上来说,是没有关系的,是两个对象。也可以两个表共用一个序列—代码上是允许的,但是开发过程中,不允许这么使用
17.数据字典其实就是表,告诉你当前用户中,有哪些表?有哪些序列?有哪些视图。。。。。
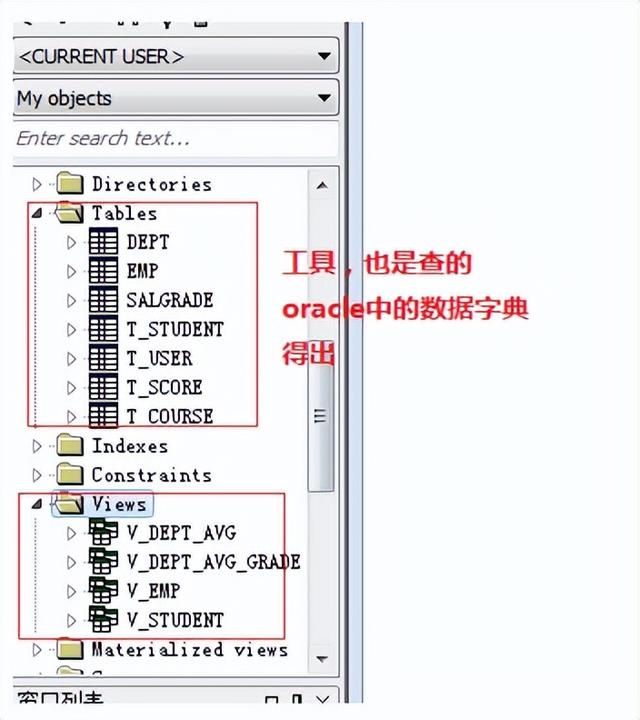
使用

有多少个数据字典?
使用dictionary

写的select 查询,如果数据量非常的大,比如有几百万,上千万的数据
查询就会很慢,一般来说查询慢,数据量有关,还有sql的复杂程度
比如:看小说,看到第50章,下一次再看的时候,是从第一章开始翻么?
--从目录选择第50章,直接跳转到页面
数据库查询,比如查empno=7934,一般执行流程,数据库表所有数据,第一条拿出来,比较,
不是—》继续拿下一条,比较
是—》返回查询结果
比如查sal
表中,需要所有的数据,全部一条一条比较。
oracle中,使用索引,进行快速定位

索引:
1) 列要有索引
2) where条件要有 带索引的列
怎么知道我的sql语句有没有走索引
查看sql语句的执行计划
pl/sql工具 选中要执行的sql语句—》F5
SQLDevelop F10
全表扫描:

走索引:

什么字段适合建立索引?
主键,唯一键,肯定是适合,值重复率低(主键、唯一建没有重复)
值重复率高: 比如性别 --不适合
select * from emp where sex=1 and sal = 800
索引不能滥用
1) 索引是占用空间的
2)当表中的数据更新的时候(增删改),索引是需要同步维护,增加更新操作的消耗
走索引: 列要有索引,第二个:where条件要有这个列,一般来说,满足这两个条件,sql语句就会走索引
1)使用like,如果是% _ 打头,不走索引

2)隐式转换,不走索引

3) 字段使用函数,不走索引

要使用索引,那就要给表创建函数索引
4)使用不等于,不走索引

5)使用not in

索引创建:
1) 表中的主键,唯一建,系统会默认创建索引
2)手动给单列创建索引


3)函数索引


4)联合索引


如果where条件不全:全表扫描

当前事务没有提交数据,那么别的事务中查不到未提交的数据。
可以查到别的事务未提交的数据,需要修改数据库的事务隔离级别
oralce有默认事务隔离级别

过程式的编程语言,是对sql语句的一种补充。比如sql中没有if,没有for
19.1 基础结构declare
--变量定义
begin
--语句块
exception
--异常处理
end;
19.2 helloworld
pl/sql工具

变量定义,赋值,使用

常用类型
varchar2 字符
char 定长字符
number 数字
date 时间
boolean
binary_integer

需求:
输出员工编号为7369的员工姓名

需求升级: 输出员工编号为7369 的员工的姓名,薪资

使用into关键字进行动态赋值,查询的数据有且只能有一条

service调用dao,catch异常中:
1)日志
2)事务回滚


语法: 变量名 表名.列名%type

语法: 变量名 表名%rowtype


语法
type recode_name is recode(
属性1 类型,
属性2 类型,
属性3 类型
);
变量名 recode_name;


into 变量名要注意顺序

类似于java中的数组类型
自定义的类型,这个类型是数组形式,数组中存储的元素类型,自定义
String[] int[]
语法:
type 类型名称 is table of 存储的元素类型 index by binary_integer;
使用:
变量名 自定义数组类型名称;
定义类型为varchar(20)

使用%type

给数组单个赋值

给整个数组赋值—》失败
赋值失败 into关键字赋值,只能给单个赋值, 给数组赋值,需要使用到游标

需求:查询指定员工的薪资,如果薪资 》2500,输出“过年可以相亲了”
语法:
if 条件 then
--语句块
end if;

需求升级:查询指定员工的薪资,如果薪资 》2500,输出“过年可以相亲了”,反之,输出“再接再厉”
if else分支
语法
if 条件 then
--语句块
else
--语句块
end if;

多重if
语法
if 条件 then
--语句块
elsif 条件 then
--语句块
elsif 条件 then
--语句块
elsif 条件 then
--语句块
else
--语句块
end if;
需求:查询指定员工的薪资,如果薪资 》2500,输出“过年可以相亲了”,
薪资在2500 ~ 1500,输出“努力一把,明年回来相亲”
薪资在1500以下的,输出“多多加班了啊”

如果条件有多个?

for、while、doWhile
oracle中也有三种循环
需求: 计算1 2 3 。。。 100的和
1)loop循环(doWhile)loop
--循环体
--退出条件
exit when 条件;
end loop;

语法:
while 条件 loop
--循环体
end loop;


输出1~10



简单点说:游标就是用来放查询的list
1)游标使用a) 定义一个游标
b)定义一个变量,用于接收游标行对象数据
c)打开游标,加载数据到内存中
d)从游标中取值
e)关闭游标,清理数据,释放内存

需求: 循环输出所有员工的编号,姓名
1. loop循环游标

修改之后:

2)while循环游标

输出为空,循环没有进入
使用while循环时,用的是c%found判断的
c%found 也是用指针当前指向位置判断有数据
所以:当使用c%found判断时,一定要保证,指针已经指向了第一条数据
修改之后的代码:

总结:
使用循环取游标中的值,使用的判断是游标的两个属性
游标%notfound : 游标指针当前指向位置,没有数据,返回true
游标%found : 游标指针当前指向位置,有数据,返回true
3)for循环游标
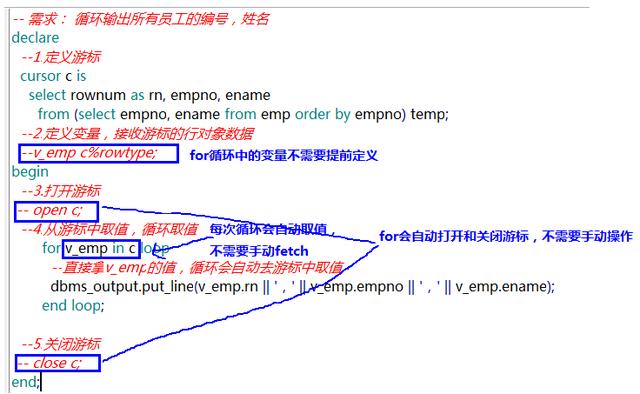

需求:
输出 平均薪资大于2500 的部门的 所有员工姓名。
输出 平均薪资小于2000 的部门的所有员工姓名。


需求:升级
输出人数最多的部门的所有员工。。。。--》新定义游标
输出研发部的所有员工。。。----》定义新游标。。。
所有输出的sql: 输出指定部门的所有员工
select deptno,empno,ename from emp where deptno=?
将游标设计成带参数的
3)带参游标1)定义带参游标
cursor 游标名(参数1 类型,参数2 类型, 参数3 类型…)
is sql语句

2) 打开游标的时候,传参

需求:


练习:
1) 输出所有员工的部门名称,姓名,薪资,薪资等级

2) 输出: 如果员工薪资等级 为1,2 输出员工编号,姓名,薪资,“少年,好好学习”
-- 1000
如果员工薪资等级 为3,4 输出员工编号,姓名,薪资,“少年,继续抠代码”
500
如果员工薪资等级 为5 输出员工编号,姓名,薪资,“少年,你可以去约会了”
200





bulk collect 批量取
limit 一次取多少条
19.11 pl/sql中执行sql语句1) 查询和更新语句,直接执行

2)sql语句转换成字符串,使用execute immdiate 命令执行

1.DDL语句(数据控制语句,create table。。。)只能使用execute immediate 命令执行
2.DML语句(数据操纵语句,select,update,delete)转换字符串,使用命令执行

变量:

字符串需要单引号


jdbc中的sql语句使用的?占位符
pl/sql中也可以使用占位符

加薪,update语句,使用命令运行。
20.存储过程有名字,并且可以存储在数据库的PL/SQL语句块



创建一个p_test存储过程

1.使用declare调用

2.使用命令调用

一般来说,只要有定时任务,或者说,只要有存储过程,数据库中,都会有一个日志表,一般来说是整个项目通用,也有个别功能频繁用到的,会单独一张日志表

日志表:
id, proc_name, status, bz , create_time
proc_name:存储过程名
status: 状态,开始,结束 ,异常


将记录日志的写成公共的存储过程
20.4带参存储过程
调用:

需求: 根据传入的员工编号,返回员工姓名,薪资
存储过程定义,没有return,通过参数的in/out类型来返回

调用

需求:查询出每个用户的编号和薪资,以及每个用户需要缴纳的个税
函数语法:

定义一个税收的函数


自定义函数的使用,和oracle内置函数使用一致

存储过程,函数的区别
相同点:
都是为了实现某个功能的pl/sql语句块
参数都是可有可无
不同点:
1)返回值,存储过程可以没有返回值,函数必须有返回值
2)返回值方式,函数是通过return返回,存储过程是通过参数传递的
3)返回值个数,函数只能有一个返回值,存储过程返回值可以有多个
22.定时任务项目中的定时任务,一般有三种
1)linux的corntab
比如磁盘清理,日志文件备份,比如过期的上传文件的删除。。。磁盘大小监控
2)项目(代码)中的定时任务,spring(业务层的框架)的定时任务
比如数据处理; 文件的操作,比如系统之间的文件同步
3)数据库的定时任务(oracle job)
数据处理,比如系统之间的数据同步,比如状态:比如零点判断,红包如果是前一天的,状态变为不可用
oracle定时任务: 定时调用的无参存储过程
查看系统中所有的定时任务
select * from user_jobs;
创建一个定时任务

查看:


暂停定时任务

效果

启用
sys.dbms_job.broken(1,false);
,