公司新入职了的产品经理小美因为业务需要,想搭一个数据大屏方便自己查看数据。她找开发小王申请了数仓权限,然后从技术中台里找到了数据大屏的工具,把自己平时查数据用的sql搬上去跑,结果总是报错。

小美找到了做数据产品经理的师兄小帅看了看。
小帅:你这个查询有问题,业务系统的sql不能直接搬来用。
小美:我看长得差不多啊,除了多了个分区外,不都是sql吗?
小帅:你现在建的是Hive查询,Hive SQL虽说和SQL非常相似,但是一些细节上还是有区别的。
一、Hive SQL是什么?
Hive是大数据领域常用的数据仓库组件,可以借助查询语言SQl将HDFS上存储的结构化文件映射成一张数据库表,并提供类SQL查询功能。Hive-SQL就是这个”类SQL查询功能”。Hive-SQL与SQL基本上一样,因为当初的设计目的,就是让会SQL不会编程MapReduce的也能完成处理数据工作。
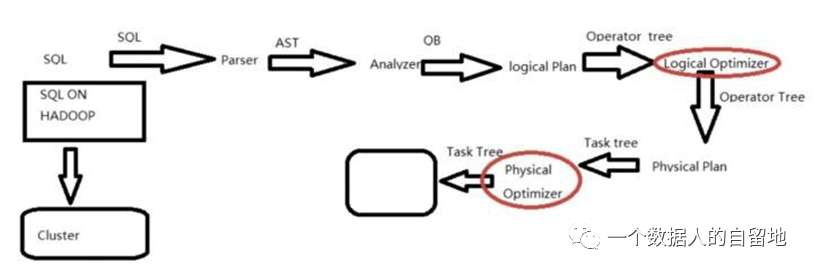
【拓展】Hive-SQL是如何转化为MapReduce任务的呢?整个编译过程分为六个阶段:
1)Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树ASTTree
2)遍历ASTTree,抽象出查询的基本组成单元QueryBlock
3)遍历QueryBlock,翻译为执行操作树OperatorTree
4)逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
5)遍历OperatorTree,翻译为MapReduce任务
6)物理层优化器进行MapReduce任务的变换,生成最终的执行计划
这里简单介绍一下其中的几个关键部分:
Antlr:Antlr是一种语言识别的工具,用来实现SQL的词法和语法解析,完成包括词法分析、语法分析、语义分析、中间代码生成等过程。使用时只需要编写对应的语法文件,定义词法和语法替换规则即可。
抽象语法树AST Tree:经过词法和语法解析后,使用 Antlr 的抽象语法树语法Abstract Syntax Tree,将输入语句转换成抽象语法树,方便后续进一步的处理。
QueryBlock:AST Tree仍然非常复杂,不够结构化,不方便直接翻译为MapReduce程序,AST Tree转化为QueryBlock就是将SQL进一步抽象和结构化。QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。我们在查看HiveSQL查询日志时会看到一个个流程块,这就是分拆出来的QueryBlock。
二、Hive SQL基本语法
小美的查询语句中用了HAVINg子句,这个是Hive不支持的,可以用子查询来代替。然后小帅为小美讲了讲HiveSQL的基本语法。
常用的显示命令
showdatabases;--查看有哪些库
showtables;--查看当前库下有哪些表
showpartitions;--查看分区
showfunctions;--罗列所有的函数
describeextendedtable_name;--查看表的结构,字段,分区等情况
常用库、表操作
createdatabasename;--创建数据库
create[external]table[ifnotexists]table_name--创建表,指定表名。external表示创建的表是否为外部表,不加此项则为内部表。ifnotexists表示该表不存在时创建该表,否则忽略异常。
[(col_namedata_type[commentcol_comment],...)]--创建字段,指定字段类型、注释
[commenttable_comment]--表的注释
[partitionedby(col_namedata_type[commentcol_comment],col_name_2data_type_2,...)]--指定分区,要注意分区字段不能出现的建表的字段中
[clusteredby(col_name,col_name_2,...)][sortedby(col_name[ASC|DESC],...)]intonum_bucketsbuckets]--分桶
[rowformatrow_format]
[storedasfile_format]--指定存储文件类型。textfile纯文本数据,sequencefil压缩数据(可节省存储空间)。
[locationhdfs_path]--存储路径
createtabletable_namelikeold_table_name;--使用like关键字复制表结构
altertabletable_namerenametonew_table_name;--更改表名
altertabletable_nameaddcolumns(col_namedata_typecomment'col_comment');--增加一个字段并添加注释
altertabletable_namereplacecolumns(col_namedata_type,col_name_2data_type_2);--删除列
altertabletable_nameadd[ifnotexists]partition_name;--增加分区
altertabletable_namedroppartition_name,partition_name_2;--删除分区
常用数据操作
insertintotable_1select*fromtable_2;--在table_1后追加数据
insertoverwritetable_1select*fromtable_2;--先将table_1中数据清空,然后添加数据
常用查询操作
HiveSQL的查询语句结构和SQL一致,除了前面提到的HAVINg子句问题外,还需要注意的是HiveSQL中没有not null,当字段为null时,使用n代替。
三、Hive SQL常用函数
小美的查询中有两处函数调用错误:
1) 用了GROUP_CONCAt()函数,这个在HiveSQL中没有,但是可以用CONCAT_Ws()函数代替;
2) 是substring_index()函数,这个应该替换成split()函数。
然后小帅为小美讲了讲Hive中的常用函数。
数学函数
bin(intd)--计算二进制值d的string值
rand(intseed)--返回随机数,seed是随机因子
round(doubled,intn)--返回保留n位小数的近似d值
floor(doubled)--返回小于d的最大整值
ceil(doubled)--返回大于d的最小整值
日期函数
current_date()--返回当前日期
unix_timestamp()--返回当前时间的unix时间戳,也可指定某一特定日期。如unix_timestamp('2021-01-13','yyyy-mm-dd')=1610513364
from_unixtime()--返回unix时间戳的日期。如selectfrom_unixtime(unix_timestamp('2021-01-13','yyyy-mm-dd'),'yyyymmdd')='20210113'
to_date(stringtimestamp)--返回时间字符串中的日期部分,如to_date('2021-01-0100:00:00')='2021-01-01'
year(date)--返回日期date的年,如year('2021-01-01')=2021
month(date)--返回日期date的月,如month('2021-01-01')=1
day(date)--返回日期date的天,如day('2021-01-01')=1
weekofyear(date)--返回日期date位于该年第几周,如weekofyear('2021-01-01')=1
datediff(date1,date2)--返回日期date1与date2相差的天数,如datediff('2021-01-01','2021-01-02')=1
date_add(date,int1)--返回日期date加上int1的日期,如date_add('2021-01-01',2)='2021-01-03'
date_sub(date,int1)--返回日期date减去int1的日期,如date_sub('2021-01-03',2)='2021-01-01'
months_between(date1,date2)--返回date1与date2相差月份,如months_between('2021-03-01','2021-01-01')=2
add_months(date,int1)--返回date加上int1个月的日期,int1可为负数。如add_months('2021-02-01',-1)='2021-01-01'
last_day(date)--返回date所在月份最后一天。如last_day('2021-01-01')='2021-01-31'
next_day(date,day1)--返回日期date后下个星期day1的日期。day1为星期X的英文前两字母如next_day('2021-01-013','MO')返回'2021-01-18'
trunc(date,string1)--返回日期所在月的第一天或所在年的第一天。String1可为年(YYYY/YY/YEAR)或月(MONTH/MON/MM)。如trunc('2021-01-13','MM')='2021-01-01',trunc('2021-02-01','YYYY')='2021-01-01'
字符串函数
length(string)--返回字符串长度
concat(string1,string2)--返回拼接string1及string2后的字符串
concat_ws(sep,string1,string2)--返回按指定分隔符sep拼接后的字符串
lower(string)--返回小写字符串,同lcase(string)。
upper(string)--返回大写字符串,同ucase(string)。
ascii(string)--返回字符串第一个字符的ascii值。
space(int1)--返回int1长度的空格字符串。
trim(string)--去掉字符串左右空格。
ltrim(string)--去掉字符串左空格。
rtrim(string)--去掉字符串右空格。
repeat(string,int1)--返回重复string字符串int1次后的字符串。
reverse(string)--返回string反转后的字符串。如reverse('abc')='cba'
lpad(string,len1,pad1)--以pad1字符左填充string字符串,至len1长度。如rpad('abc',5,'1')='11abc'。
rpad(string,len1,pad1)--以pad1字符右填充string字符串,至len1长度。如rpad('abc',5,'1')='abc11'。
split(string,pat1)--以pat1正则分隔字符串string,返回数组。如split('a,b,c',',')=["a","b","c"]
substr(string,index1,int1)--从index位置起截取int1个字符。如substr('abcde',1,2)='ab'
regexp_replace(string1,string2,string4)--正则表达式替换函数。将字符串1中的符合正则表达式string2的部分替换为string3。如regexp_replace(‘abcde,‘b|c|d’,”)=’ae’
聚合函数
count(col)--统计行数
sum(col)--统计指定列和
avg(col)--统计指定列平均值
min(col)--返回指定列最小值
max(col)--返回指定列最大值
窗口函数
row_number()over(partitiionby..orderby..)--根据partition排序,相同值取不同序号,不存在序号跳跃
rank()over(partitionby..orderby..)--根据partition排序,相同值取相同序号,存在序号跳跃
dense_rank()over(partitionby..orderby..)--根据partition排序,相同值取相同序号,不存在序号跳跃
lag(col,n)over(partitionby..orderby..)--查看当前行的上第n行
lead(col,n)over(partitionby..orderby..)--查看当前行的下第n行
转换函数
cast(colasdtype)--将指定值转换为指定数据类型dtype,如字符串到整型的转换
判断函数
NVL(expr1,expr2)--如果第一个参数为空则显示第二个参数,反之则显示第一个参数。常用于非空判断,如nvl(table1.name,'')<>''
NVL2(expr1,expr2,expr3)--如果第一个参数为空则显示第二个参数,反之则显示第三个参数
NULLIF(expr1,expr2)--如果第一个参数和第二个参数相等则返回空(NULL),否则返回第一个参数
Coalesce(expr1,expr2,expr3….exprn)--返回参数序列中第一个非空参数
解析函数
regexp_extract(string1,stringpattern,int1)--正则表达式解析函数。将字符串string1按照正则表达式pattern的规则拆分,返回int1指定的字符。如regexp_extract(‘foothebar’,‘foo(.*?)(bar)’,1)=’the’,regexp_extract(‘foothebar’,‘foo(.*?)(bar)’,2)=’bar’
Size(map(
find_in_set(string1,stringstrList)--返回string1在strlist中第一次出现的位置,strlist是用逗号分割的字符串(集合)。如果没有找string1,则返回0.
parse_url(stringurl_string,stringpartToExtract[,stringkeyToExtract])--url解析函数,partToExtract的有效值为:HOST,PATH,QUERY,REF,PROTOCOL,AUTHORITY,FILE,andUSERINFO。如parse_url(‘
&k2=v2#Ref1′,‘QUERY’,‘k1′)=’v1’
get_json_object(stringjson_string,stringpath)--json解析函数。解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
行列转换
concat_ws(sep,collect_set(col1))--多行转一列,以sep分隔符分隔。collect_set在无重复的情况下也可以collect_list()代替。collect_set()去重,collect_list()不去重
lateralviewexplode(split(col1,sep))--一列转多行。
-END-