写在前面:
很多同学目前所做的业务分析工作,徒手分析即可cover业务需求,较少用到一些高阶的统计模型和机器学习上面的东西。渐渐的便会产生一种感觉,即数据分析满足业务需求即可,不需要会机器学习。
但我认为:
1、目前的工作不需要,不代表之后的工作不需要,我们应该着眼于我们整个数据分析生涯;
2、掌握一些模型可以高效做一些定量分析,较徒手分析效率更高,更准;
3、我们觉得一些东西没用,很可能是因为我们还没有发现如何去用 ;
4、我们对自己的要求不应该止于满足业务需求,一些探索性专题非常依赖于机器学习 ;
基于以上,我尝试开始更新一些机器学习方面的文章,从较基础的线性回归、决策树等开始,希望大家可以跟着小洛一起学习,有疑问大家可以随时在交流群提~
一、什么是线性回归线性回归是利用线性的方法,模拟因变量与一个或多个自变量之间的关系。对于模型而言,自变量是输入值,因变量是模型基于自变量的输出值,适用于x和y满足线性关系的数据类型的应用场景。
线性回归应用于数据分析的场景主要有两种:
驱动力分析:某个因变量指标受多个因素所影响,分析不同因素对因变量驱动力的强弱(驱动力指相关性,不是因果性);
预测:自变量与因变量呈线性关系的预测;
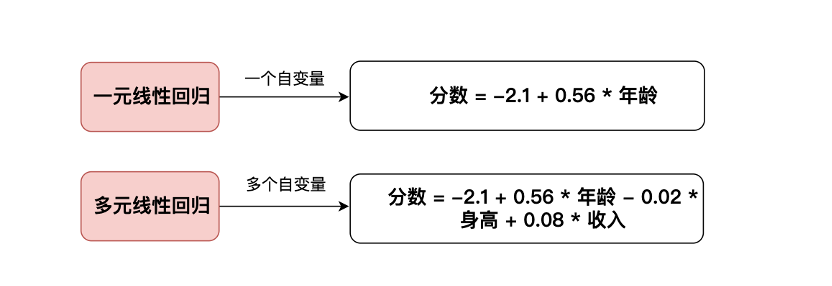
例如要衡量不同的用户特征对满意分数的影响程度,转换成线性模型的结果可能就是:分数=-2.1+0.56*年龄
线性回归模型分为一元线性回归与多元线性回归:区别在于自变量的个数
我们知道了模型的公式,那么模型的系数是如何得来呢?我们用最小二乘法来确定模型的系数。最小二乘法,它通过最小化误差的平方和寻找数据的最佳函数匹配,利用最小二乘法可以求得一条直线,并且使得拟合数据与实际数据之间误差的平方和为最小。
将上述模型公式简化成一个四个点的线性回归模型来具体看:分数=-2.1+0.56*年龄
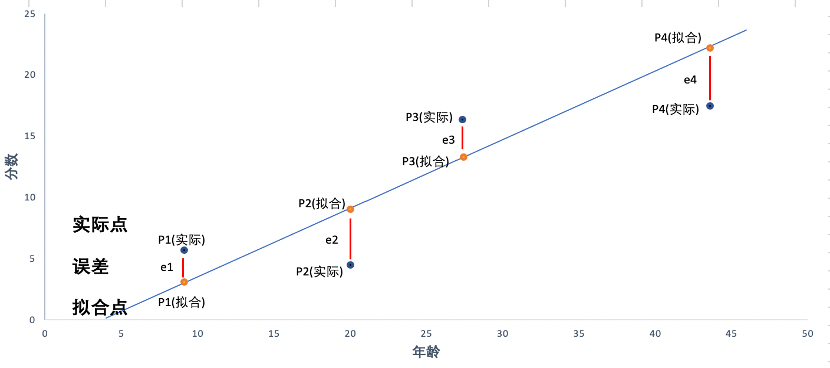
最小二乘法选取能使模型最小化的直线,生成直线后即可得出模型自变量的系数和截距。
三、决定系数R方(R-squared)与调整R方R方(适用一元线性回归)R方也叫决定系数,它的主要作用是衡量数据中的因变量有多准确可以被某一模型所计算解释。公式:

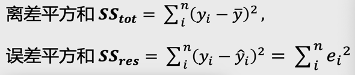
离差平方和:代表因变量的波动,即因变量实际值与其平均值之间的差值平方和
误差平方和:代表因变量实际值与模型拟合值之间的误差大小

故R方可以解释因变量波动中,被模型拟合的百分比,即R方可以衡量模型拟合数据的好坏程度;R方的取值范围<=1,R方越大,模型对数据的拟合程度越好;
使用不同模型拟合自变量与因变量之间关系的R方举例,
R方=1 模型完美的拟合数据(100%)
R方=0.91 模型在一定程度较好的拟合数据(91%)
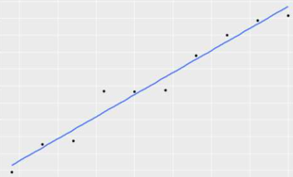
R方<0 拟合直线的趋势与真实因变量相反
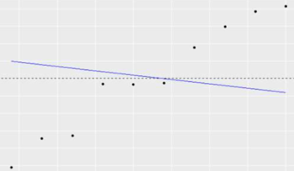
一般的R方会存在一些问题,即把任意新的自变量加入到线性模型中,都可能会提升R方的值,模型会因加入无价值的变量导致R方提升,对最终结果产生误导。
故在建立多元线性回归模型时,我们把R方稍稍做一些调整,引进数据量、自变量个数这两个条件,辅助调整R方的取值,我们把它叫调整R方,调整R方值会因为自变量个数的增加而降低(惩罚),会因为新自变量带来的有价值信息而增加(奖励);可以帮助我们筛选出更多有价值的新自变量。
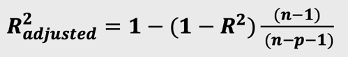
n:数据量大小(行数)->数据量越大,新自变量加入所影响越小;
p:自变量个数->自变量个数增加,调整R方变小,对这个量进行惩罚;
一句话,调整R方不会因为模型新增无价值变量而提升,而R方会因为模型新增无价值变量而提升!通过观测调整R方可以在后续建模中去重多重共线性的干扰,帮助我们选择最优自变量组合。
R方/调整R方值区间经验判断四、线性回归在数据分析中的实战流程
<0.3->非常弱的模型拟合
0.3-0.5->弱的模型拟合
0.5-0.7->适度的模型拟合
>0.7->较好的模型拟合
我们以共享单车服务满意分数据为案例进行模型实战,想要去分析不同的特征对满意分的影响程度,模型过程如下:
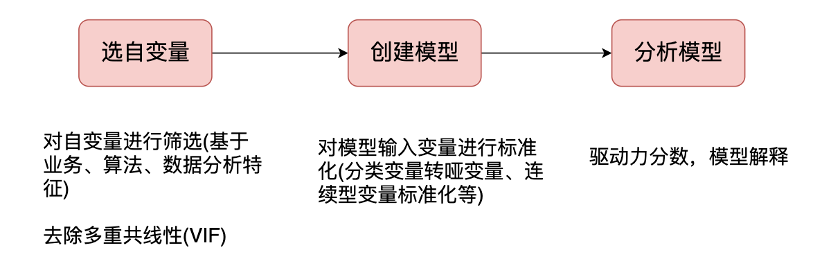
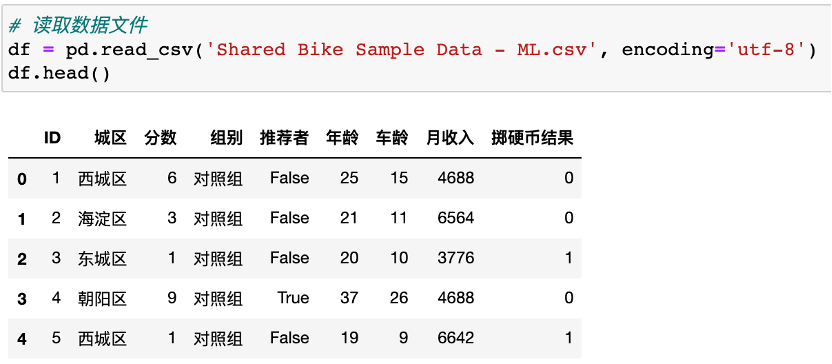

多重共线性:就是在线性回归模型中,存在一对以上强相关变量,多重共线性的存在,会误导强相关变量的系数值。
强相关变量:如果两个变量互为强相关变量,当一个变量变化时,与之相应的另一个变量增大/减少的可能性非常大。
当我们加入一个年龄强相关的自变量车龄时,通过最小二乘法所计算得到的各变量系数如下,多重共线性影响了自变量车龄、年龄的线性系数。
这时候,可以使用VIF消除多重共线性:VIF=1/(1-R方),R方是拿其他自变量去线性拟合此数值变量y得到的线性回归模型的决定系数。某个自变量造成强多重共线性判断标准通常是:VIF>10
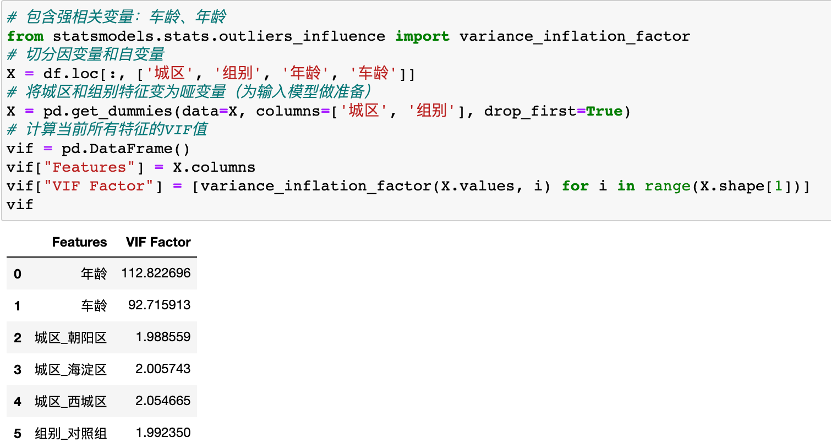
我们发现,年龄的VIF远大于10,故去除年龄这一变量,去除后重新计算剩余变量VIF发现所有均<10,即可继续。
4、计算调整R方
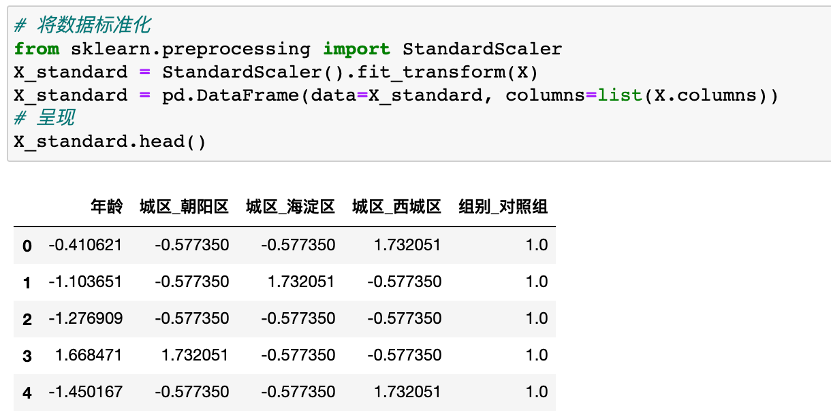
我们希望不同自变量的线性系数,相互之间有可比性,不受它们取值范围影响
共享单车分数案例,因变量是分数,自变量是年龄、组别、城区,线性回归的结果为:分数 = 5.5 + 2.7 * 年龄 +0.48 * 对照组 + 0.04 * 朝阳区 + 0.64 * 海淀区 + 0.19 * 西城区
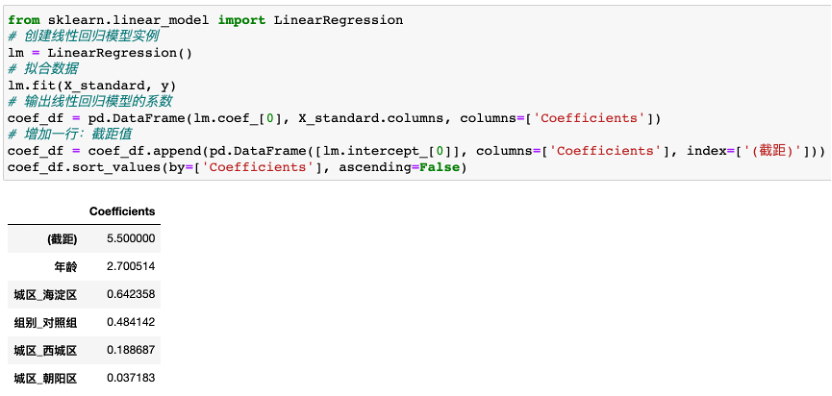
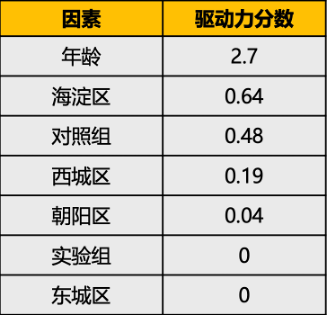
最终产出不同用户特征对用户调研分数的驱动性排名。驱动力分数反应各个变量代表因素,对目标变量分数的驱动力强弱,驱动力分数绝对值越大,目标变量对因素的影响力越大,反之越小,驱动力分数为负时,表明此因素对目标变量的影响为负向。
8、根据回归模型进行预测至此,回归模型已经建好,预测就不写了,把要预测的数据x自变量导入模型即可预测y。
结语:相信大家读完这篇文章,对线性回归模型已经有了一些了解,大家快快动起手来把模型应用到自己的实际工作中吧!
-END-