上文咱开了个头,给大家分享了一下什么是FSLDM,以及FSLDM是怎么切分主题域的。我们简单回顾一下:
建模的核心是对现实世界的抽象。一个好的模型应该是稳定的,是灵活、可扩展的,是规范的,是中性的、通用的。
这其中最重要的,不是稳定,不是灵活、可扩展,不是规范,而是中性、通用。
我们建的模型应该把抽象出来的对象尽可能的打散、重组,然后抽象、再重组,直到能够非常通用才可以。
因为只有这样,我们建设的模型,才能为同类型的新业务服务,甚至外延到其他BU。才可能稳定、灵活、可扩展。LDM位置上次其实忘记说一个很重要的点:LDM是干啥的。在流程图中,LDM已经搞定到逻辑建模这个位置了:
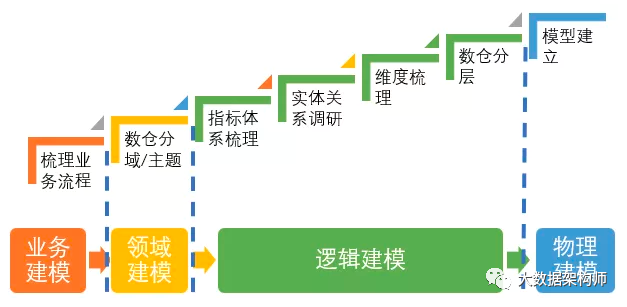
但是在数据仓库的架构中,它的位置处于中间这个位置:
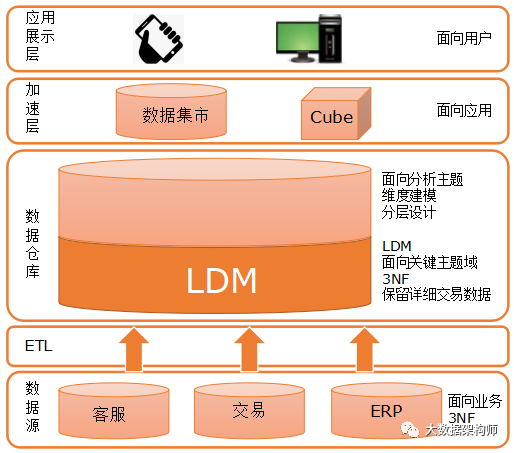
有同学就好奇了,为啥LDM会在这里呢?为啥LDM不把上面的维度建模也搞定呢?还有上面的Cube也建起来,不是更牛X么?
昨天群里有个同学也问,DWD层宽表的元素构成主要考虑那些因素?是要更多的考虑下一层所需的灵活性,多弄一些字段,还是为了降低存储压力,减少一些字段呢?
这就得回到分层建设的核心目标是什么。你认为是什么?
分层是为了解耦。
解什么的耦?解业务和数据的耦。这也是LDM为什么要通用的原因。LDM通用了,上层的业务随便改,下面的LDM不用改。下面的数据结构变了,LDM也不用大改。
所以回到文章最开始说的,什么是好的模型?为什么要做到灵活性、稳定性、通用性?
因为要解耦。
好,刚才那位同学的问题,你觉得应该怎么回答?
首先第一点:现在存储很便宜,所以不需要节省存储空间。
第二点:单纯的追求灵活性是不够的,极致的灵活,就是所有的数据都存,也就是现在的数据湖的套路。
OK,我个人的理解是这样的:DWD层可以不用考虑节省存储的问题,必须要追求灵活性,但是同样要考虑到通用性、规范性和稳定性。所以,合适的抽象和选择,是更重要的。但是如果是灵活性和存储两个选项,我选灵活性。
因为LDM的任务是解耦,为了节省空间,失去了解耦的灵活性,就舍本逐末了。
不过,尽信书不如无书。我们学习经典,也要跟追时代的步法,否则就变成老古董了。
上图中,业务系统和LDM都必须遵循三范式。但是现在互联网行业由于高并发的场景,业务库设计的时候就已经退化范式了,尤其是一些大数据环境,从工具层面就已经退化了。所以我们得结合实际去看哈。
当事人主题域上篇文章里,我们看了一下FSLDM的十大主题域,分别是:当事人、资产、财务、区域、营销活动、协议、事件、内部组织、产品和渠道。
下面,我们拿其中一个主题域详细说说,看看他们具体是怎么设计的。
先上定义,比较枯燥,嫌费劲可以先略过:
当事人是指任意的个人或团体。比如:客户、潜在客户、各种组织、雇员、银行分行、内部部门等等。是客户概念的外延,能支持不同的关系(父子、雇佣、夫妻等);可以是一个具备相同目的的个体组合,如协会、社会团体、家庭、亲友团等;可以是一个外部或内部的组织机构。
然后呢?为啥要叫“当事人”?叫“客户”不行么?想解释这个问题,很简单,看你要解决多大的问题。
如果你要说抽象到客户一层,也可以。但是你还得弄一个“员工”。而且出现内部员工也是客户的情况咋办?保险的客户和基金的客户是一样的吗?医院的病人是不是也可以算是客户的?学校的学生呢?
哥们是不是觉得我在抬杠?有哥们会说了,我*,直接抽象成人不就完事了?整那么复杂!
嘿嘿,真的吗?企业是否也可以成为我们的客户?可以吧?那你是不是还要出现一个企业的实体?嗯?搞定企业就行了?我能不能发展政府部门的生意?
你是不是想说加一个字段区分啊?
嘿嘿,光有一个字段区分还不行,因为个人、公司和政府的唯一码不一样,所以可能还得分两张表。而且,他们的层级、关系都不一样,购买的产品和对应的政策也都是两套。你看,晕了吧?
之所以出现这些问题,是因为抽象的还不够高。当然,不是说抽象的越高越好啊,咱还得根据咱的实际业务去走。
比如FSLDM的当事人定义为:“任意个人或者团体”,这从最根本上就解释了:“我们是为谁服务的”这个问题。同理,IBM的BMDW也不是客户,而是关系人。
然后咱再往下梳理:当事人有几种?不同的当事人的属性也不一样,那必须得分开啊。他们之间是否还有层级关系?也要体现出来了。
所以,FSDLM当事人的模型就是就是这么构建的(懒,没用PD,大家凑合看哈,意思到了就行):
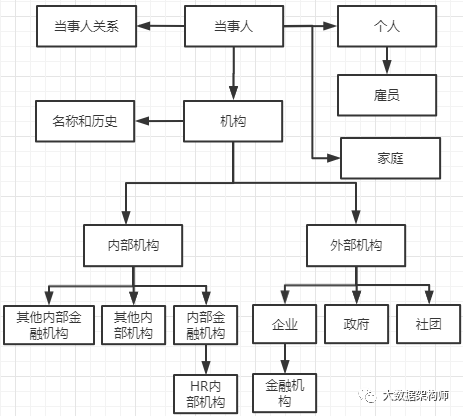
这样的结构可以完美解决上述的各种问题。最上一层,抽象为当事人,往下分为个人和团体机构。
个人和团体各自有自己的细分、关系、属性,各自分的清清楚楚,明明白白的。
个人又会衍生出两种不同的关系,一种是家庭,一种是员工。
机构呢,则细分为内部机构和外部机构,各自又有细分和上下级关系。
个人与个人、个人与家庭、机构与机构、个人与机构,都是可以发生任意关系的,这些关系都会在关系表中。
所以什么是检验模型好坏的标准?是你设计的模型,能够承接当前商业环境下任意的业务关系。
不好的模型是什么样的?这边业务逻辑稍微变一点,数据模型就没法支撑,就得加字段、加表,甚至重构。
到这里就结束了吗?远远没有。
前面说过,FSLDM第一层是10个主题域,第二层是50多个实体,第三层是近3000个实体和一万多个属性,以及300多个逻辑模型。
10个主题域我们说过了。并且选了其中一个,阐述了其中“当事人”领域,学习了他们是怎么抽象一个能够支撑核心业务的核心实体,以组建“当事人”主题域的。再往下一步就得再解剖一个核心实体,看看这个实体具体怎么设计的。
个人实体很多人具体到建更细的实体的时候,就会有各种问题,这个属性怎么关联?有共性的该咋弄?这个是不是要单独建一个属性/实体等等。
其实这些问题我也不能给你准确的答复,也没有一个绝对标准的回答。在建模这块,基础的共识是:根据建模师的经验和喜好,比较自由的去构建。
这个有点像建筑设计师的感觉。只要结构合理,力量支撑到位,对下层的操作数据友善,对上层的业务拓展开放,就是一个非常好的建模。
在FSLDM的当事人主题-个人域中,是这样构建的(图片不严谨,凑合看哈):
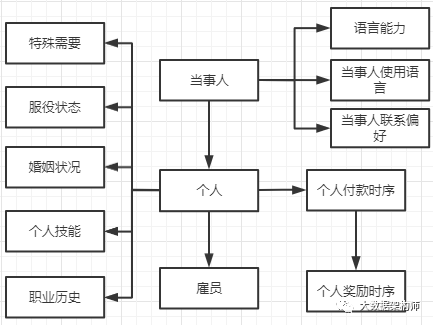
中间是当事人-个人主题域的层级关系。这里核心实体有3个:当事人、个人、雇员。
为什么语言放在当事人实体上呢?我们思考一下,当事人除了人,其实还有组织机构。组织机构其实也是有语言偏好的。好比我们给各大领事馆打电话,用他们的官方语言是尊重的表现,即便是他们也懂中文。
但是职业历史、个人技能、婚姻状况等就只能放在“个人”实体上了。而下面雇员其实也有自己的属性,这我就没画出来了。
在个人层面,各种属性就不说了,根据业务要求来。请注意右侧,还有一个付款时序和奖励时序。这两个就跟银行的业务关系非常紧密了,而且后续可以做很多的业务洞察。
有人说了,那银行保险之类的公司最重要的不是额度、签约历史、联系方式、身份验证等,这些信息在哪里?
嘿嘿,这些信息是非常重要,但是不单单是只有个人才有哦!机构也是有的。所以这些统统都放在“当事人”那一层,比如这样:

并且,因为额度、身份、签约、联系信息等内容其实都是会变化的,有些信息变化可能还会很频繁,所以建历史表是最合适的了。
那跟其他主题域发生关系咋弄?你得有一个区域,专门放当事人跟其他主题域的关联关系。
那有其他业务怎么办?具体看是什么业务,如果是核心业务,比如协议、产品,用上面的关联关系直接连通到其他主题域。
如果是风险、信用报告、资产和负债等与当事人关系非常紧密的,单独划分一个个的小区域,专门存放这类模型。
所以当事人这个大的主题域下,还会细分以下部分:
个人、机构业务、机构信息、关系、分类、风险、信用报告、资产、负债等等。
每个小块中都是以当事人为核心,各自展开。当然,关注的内容、建立的实体、关系都完全不一样,相互独立,却有互相关联、支撑。这有点MECE的那个意思。
顺序这一个主题域我们说完了,这还有9个呢。怎么搞?按什么顺序建呢?有些同学喜欢按照重要程度去建设,前面不是已经整理出来了么?跟其他主题域关系最紧密的就是啊。那就是当事人、协议和组织了。
这个逻辑很有道理,但是你贸然决策,就肯定会踩坑。因为有些领域是非常个性化的,非常耗费时间,有些领域还没啥产出。
而且,你评判主题域是否重要的指标是什么?跟其他领域的关系密切程度吗?那个的确能代表重要程度,但是这同样也代表了复杂程度啊。
我的经验是重要性+价值度,评价出优先级别。这样的好处是边建设,边有业务产出。
不过FSLDM的建设逻辑既不是按上面说的那种重要程度排序,也不是按重要+价值综合评定,而是按这个逻辑:

这也是分轻重的,但是有没有发现规律?那就是除了重要、价值两个维度之外,还有一个“数据”的维度。
为啥要加这个维度?因为没参考数据,建模的工作就是空对空啊,全凭想象。而且,建模之后有一个非常关键的动作,就是模型的验证。没数据,也没办法验证你这个模型的好坏。
所以,加入数据因素,综合评判,更适合建模工作的推进。
你是不是好奇FSLDM的建模工作推进流程?这个当然不能少了!
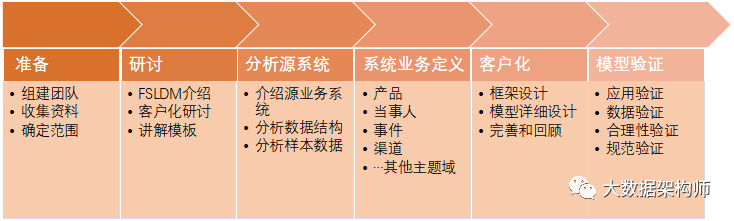
简单来说,项目得分准备、研讨、分析源系统、业务定义、客户化和模型验证6个环节。
不过这个参考意义不大,因为他们已经有标准模型了,相当于是改装车的工作流程,而不是造车的流程。
其中比较有意思的环节是研讨环节。这个环节相当于是在拉平认知。后面的事情就好办了。
为什么说参考意义不大呢?因为现在,已经没有哪个公司愿意这么做了。主要的原因一言难尽呐!如果你感兴趣,就继续点“在看”,我看有没有足够的动力,推动我去吐槽一下现在行业数据仓库工作状态和未来发展方向。
结语建模是一件非常考验数据建模工程师功底、专业性极强的工作。模型架构的合理不合理,完全取决于你对于业务的理解、对于方法的熟练掌控能力,以及对于数据的结构性架构的能力。
提升能力的方法,最好的办法就是阅读经典,理解、掌握其内在逻辑,不断的思考、总结、提炼,然后在实践中磨炼。祝好!
感谢阅读,本次分享的内容就结束了。本公众号目前保持日更3000字,为你提供优秀的数据领域的分享。本篇如果有帮助的话,还请点赞、在看分享一波!
欢迎大家加我微信好友,尽个点赞之交,有需要的可以拉你进数据建模交流群,2021更上一层楼!
推荐阅读:
数字化转型案例失利的3大原因 by 彭文华
数仓的建模和BI的建模有啥区别?by彭文华
一口气讲完数据仓建模方法--数据仓库架构师碎碎念
传统数仓和大数据数仓的区别是什么?
传统数据仓库转型最佳目标:Kylin!
更多精彩: