这是我的第42篇原创
今天聊聊分布式环境下数据一致性的各种解决方案。有点烧脑,但是很有趣。
单体环境中的一致性问题在传统关系型数据库环境(单体环境,或者叫单机)中,自己记录自己的就行了,单机环境不存在环境数据一致性的问题,倒是有并发操作数据一致性的问题。
对于一个数据库操作(专业术语叫:事务)来说,总结出4个特性:原子性、一致性、隔离性和持久性,合称ACID,我们不需要记那么多,只需要知道这些特性就是能保证数据库里的数据能够准确就行了。
原子性(atomicity):一个事务中的所有操作,不可分割,要么全部成功,要么全部失败;
一致性(consistency):一个事务执行前与执行后数据的完整性必须保持一致;
隔离性(isolation):一个事务的执行,不能被其他事务干扰,多并发时事务之间要相互隔离;
持久性(durability):一个事务一旦被提交,它对数据库中数据的改变是永久性的。
为了防止很多人一起操作,数据库会大量使用锁。锁就是在你操作这条数据的时候,加一个状态位,别人就无法操作了,类似于你上厕所的时候锁门一样 。
。
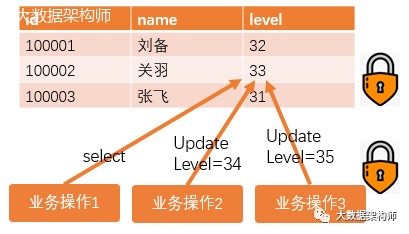
在上图中,有两个业务操作同时要修改关于的等级,但是业务操作3拿到锁了,所以操作之后,关羽的等级会变成35。业务操作2会因为这条记录被锁,而执行失败。
单机数据库环境(传统数据库),用的大多是悲观锁,意思就是用悲观的态度对待数据库修改,假定任何一次拿数据都可能遇到有人会修改:
在你修改这条数据的时候,数据库会自动帮你对条记录上个锁,别人就无法在你改数据的时候同时修改了,这叫行锁;
在你改这个表的时候,数据库也会给表上锁,这叫表锁;
在你读取数据的时候上锁,就是读锁;
在你写数据的时候上锁,这就是写锁。
但是分布式环境,就不一样了。锁是面对并发任务的,解决多个任务抢一个资源的问题。分布式的时候也会面临这个问题,用的是分布式锁解决。
但是分布式本身会导致另外一个问题:分布式是集群环境,集群环境会存储多个副本,这个时候问题来了,既然一份数据会存储多个副本,集群怎么保证多个副本中的数据都是一样的?又怎么最终保证修改完数据后,我们去读取这个数据,就是刚刚改好的数据呢?
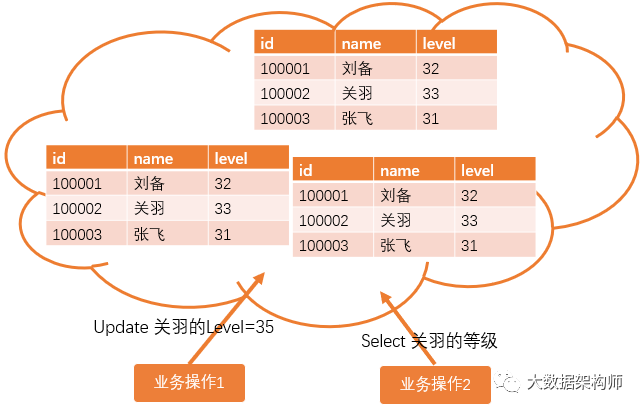
之所以有这个问题,就是因为分布式环境是多个小数据库组成集群,而网络通讯出现异常是集群建设的前提假设。也就是说,当业务操作1修改关羽等级的时候,就可能出现三个副本的数据不一致的情况。副本1、2已经改好了,副本3因为网络延迟,还没改好;这时业务操作2读取关羽等级的时候,如何保证能读取到最新的数据?这就是分布式环境中的数据一致性的额问题。
CAP定理为了研究分布式数据一致性的问题,IT届吵吵了很久,2000年,Eric Brewer在国际会议上提出了CAP猜想,2002年,Lynch与其他人证明了Brewer猜想。这个被证明的CAP定理如下:
C一致性,即所有副本的数据都是一致的;
A高可用性,即一部分节点出现故障,能够响应客户端的读取请求
P分区容错性,分布式环境中,即出现网络分区时,也能使客户端拿到最新数据
CAP无法同时满足,最多只能同时满足其中两项。
其中P(分区容错性)是必须的,也就是说,我们只剩下CP和AP两个选择。要么抛弃数据一致性,追求高可用,要么抛弃高可用,追求数据一致性。而这两个结果都不是我们想要的。这可咋办?
base理论这个世界总是有英雄站出来。eBay的架构师Dan Pritchett提出了base理论:
Basically Availble,基本可用(CAP中的A,高可用)
Soft-state,软状态/柔**务
Eventual Consistency,最终一致性(CAP中的C,数据一致性)
所有的非金融的应用场景中,我们都遵循base理论,提供基本可用和最终一致性的服务。
Quorum机制正是基于CAP和base理论,才有了Quorum机制,来解决分布式环境中数据一致性的问题。quorum机制又叫NRW机制,允许集群中有不一样的情况,但是只要能保证读取的时候有新的数据就行了,NRW即:
N=总节点数
R=read,读取的副本数
W=write,写入的副本数
拿到最新数据所需要读取的副本数共需:R=N-W+1,W越大,写入的概率越小,读取的压力就越小;W越小,写入的概率越大,但是读取的节点数就越多,读取的性能越差
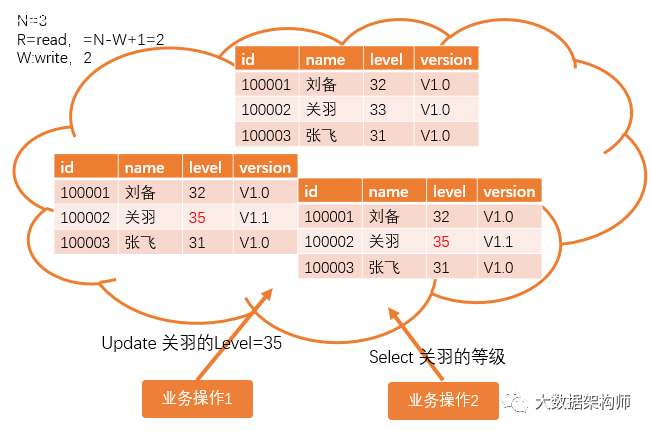
以上图为例,假设业务操作1进行修改关羽等级的时候,只有两个节点修改成功了,那么业务操作2进行读取的时候,必须要读取R=N-W+1=3-2+1=2个副本就能获取到最新的数据。你看,我们无需所有节点都一致,也能达成数据可用的效果。至于那个还没改好的节点,集群的数据同步机制会慢慢同步的。
那么有没有让所有节点都一次性全部成功写入的方法呢?有的,方法还不少。
强一致性解决方案目前主流的强一致性解决方案有4种:
2PC(2 phase commit)2阶段递交法
3PC(3 phase commit)3阶段递交法
4PC(笑)TCC(try-cancel-commit)试一下,不行就算了递交法
消息中间件一致性解决方案
基本上跟TCP/IP三次握手的逻辑是一样的,2PC就是经过两个阶段,最后递交事务;3PC就是经过3个阶段,最后递交事务;TCC就是尝试、取消、递交;Half MQ就是先占坑,确认后再递交。
2PC
2PC分为两个阶段:投票阶段和操作阶段。既然是投票,就得有一个人从中协调,要不怎么保证公平呢。所以2PC引入了一个协调者coordinator。一个分布式事务请求过来,先到协调者这边,协调者发起第一阶段即投票阶段,问所有的参与者:你们准备好了吗?所有人回答:准备好了!然后协调者发起第二阶段即递交阶段说:兄弟们,改吧。然后所有参与者发起本地事务把关于的等级改成34级。如果有人说:我这还没好,那么协调者也会发起第二阶段,只不过就变成了取消操作。
这就跟跑步比赛一样,第一阶段:裁判喊“准备~~”;第二阶段:裁判喊“跑”!
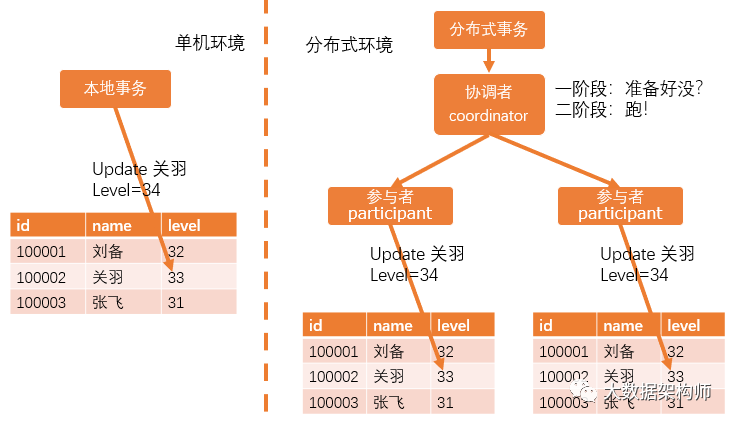
2PC比较耗资源,因为所有人的资源都锁着,一直等到所有人都答复了才能递交/取消,万一有节点甚至是协调者掉线那就麻烦了,全得等着。
3PC
3PC是在2PC的基础上做了一些优化,在2PC的两个阶段之间,增加一个“预执行”Percommit的阶段,这样就变成了3个阶段:CanCommit、PerCommit、DoCommit。
这还跟跑步比赛一样,第一阶段:裁判喊“各就位~~”;第二阶段:裁判喊“预备~~~”;第三阶段:裁判喊“跑”!
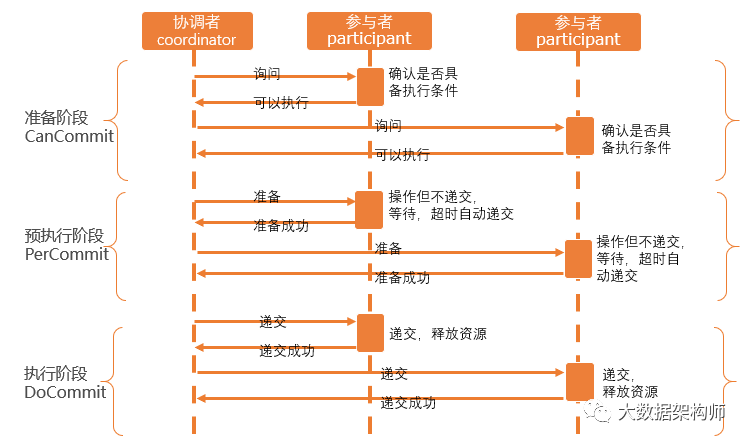
3PC由于增加了预执行的操作,不会造成长时间锁资源,而且增加了超时自动递交的规则,效率大大增加。
但是万一有些节点超时的时候,有些节点告诉协调者他准备失败,然后协调者取消了任务咋办?这样还是会导致数据不一致。
TCC
TCC实际上是在业务逻辑层实现的,就是写业务代码的程序员完成的。2PC、3PC都是资源层实现的,是底层的逻辑封装好的。TCC就是Try、Cancel、Commit,这不是跟2PC一样的么?准备-取消or执行。所以很多程序员在看TCC和2PC的时候会感觉这俩很像。TCC的优势是应用自己定义数据库操作的粒度,降低锁的冲突,提高吞吐量。
TCC的问题在于每个业务都要写一次TCC。太繁琐了。有没有更好的解决办法呢?
消息中间件一致性解决方案
其实消息中间件的一致性解决方案分为普通MQ和Half MQ 半消息(事务消息)。
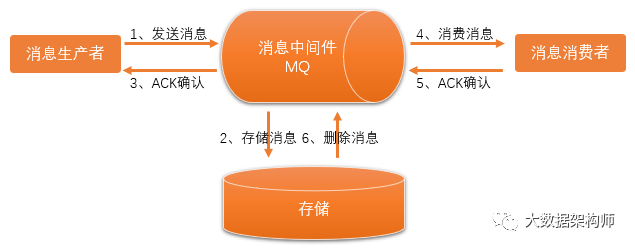
现在我们不需要老是询问了,也不需要在业务逻辑里总去做各种尝试了。直接把需要别人改的东西扔到MQ里,其他组件到MQ里定时消费消息,按要求执行就OK了。完全解耦,简直完美!
但是MQ本身就有一些小问题,比如上游应用处理完了,把消息扔到MQ的时候出现问题了,那就完蛋了,前后数据就不一致了。这时候就需要半消息(事务消息)出场了。
Half MQ的意思就是把消息再分成两次,做一次类似于2PC的操作。
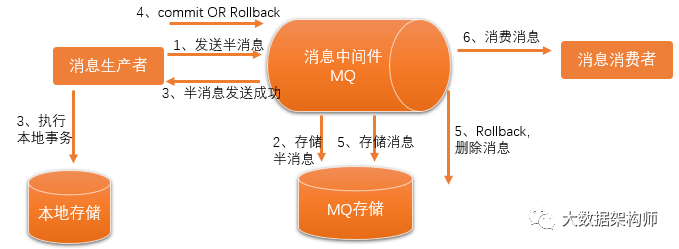
这样就避免了普通MQ的管杀不管埋的弊端。生产者需要等半消息确认成功后,才开始写本地事务。MQ这边已经确认消息ok,再投递给消费者,消费者那边进行消费就行了。
我们发现,一个很简单事情放到分布式环境之后就变得非常复杂。就好比是自己做决定和让集体做决定一样,太难了。自己决定的话,自己说了算就行了。集体决定得需要各种各样的规则,要不就大家各说各的,吵成一团。
好在计算机比人要简单的多,我们怎么说,它就怎么做。比起人来说,还是计算机要容易对付的多啊。
还有,各种问题,总是有解决方案的,我们总是在无穷逼近完美之中,但是貌似又不是能完美解决,总是有一些小小的问题。我站在巨人的肩膀上,感叹世界的不完美,是不是太作了?
以上~~~
干货|架构师的视角看透中台底层规则 |论数据驱动业务的“力”
热文|大数据工程师体系职业路径全解
帮我点击“点赞”+“在看”的,今年都涨工资!