这是我的第74篇原创

kafka+SparkStreaming是目前lambda架构里比较流行的实施任务处理。但是里面的坑还是不少,没经历过的朋友得踩不少坑。
At most once:一条记录要么被处理一次,要么没被处理。用人话说,就是会丢数据。
这种语义其实就是使用Receiver直接接收Kafka的数据。Receiver接收数据后,存储在Spark的执行器中,Spark Streaming启动的作业会去处理数据。
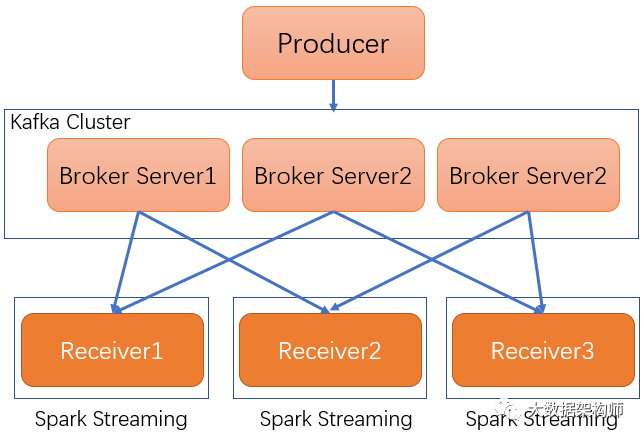
一般情况下,Receiver是单点的,单点肯定就有丢数据的风险啊!Spark Streaming都是在内存里操作,一旦Receiver单点故障,数据就丢失了。所以这种方案是大家不能容忍的。
Spark 1.2的时候,有一个补充方案,就是启动Write Ahead Logs,将接收到的数据固化下来。一旦Receiver单点故障了,重新启动的时候再去恢复一下就好了。不过这个方式实际上是把数据复制了两次(kafka自己复制,Spark又复制一次)性能不太好。
atLeastonceAt least once:一条记录可能被处理一次或者多次。用人话说,就是会重复消费数据。
为了避免丢数据的弊端,Spark1.3中引入了 Direct Approach机制从kafka获取数据,替代原有的Receiver接收器。
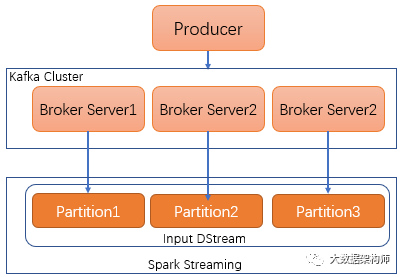
SparkStreaming的KafkaCluster会先获取kafka的partition信息,然后创建DirectKafkaInputDStream,对应每一个Topic,然后获取每个Tiopc的每个Partition 的Offset。这样等于是在SparkStreaming中对Kafka的每个Topic的每个Partition都建立了一个专属数据管道,直接接收数据。另外,所有的Offset信息都会报给InputInfo
Tracker。
这样的好处很多哈,比如简化并行、避免重复复制数据、降低资源等等。
但是这样会出现一个问题,特殊情况下可能会重复消费。比如在上报offset之前出故障了,任务重启之后,重新获取的offset是以前的,然后把当前处理进度的数据又重新读取了一次。
Exactly once:一条记录只被处理一次。用人话说就是,数据这么算就准了。
重复消费的原因其实就是在于处理数据和递交Offset是分两步走的,也就是说不在同一个事务里。
想不重复消费,那就要做到幂等或者事务更新就行。
不过光搞定处理数据和递交offset事务更新还是不够,万一数据不能重复消费也是白搭。所以要做到Exactly once,得有三个前提:
1、数据源端支持数据重复读取;
2、流计算引擎支持Exactly once;
3、第三才是Sink支持幂等或者事务更新。
Spark Streaming搞定Exactly once的方法其实还是利用kafka支持数据重复读取+Spark Streaming的DStream支持Exactly one+事务更新和数据持久化。
这样,一旦发生故障,要么数据没处理完,offset也不会同步递交;部分数据进行持久化;这样任务恢复后,获取的offset和数据状态是同步的,就不会重复消费数据了
配合以下文章享受更佳
干货| 12种方法,彻底搞定数据倾斜!
干货|设计思想赏析-MapReduce环形缓冲区
干货 |传统数仓和大数据数仓的区别是什么?
我需要你的转发,感谢你