这是我的第83篇原创

所有的数据处理工具都面临数据高可靠、高可用的问题,一旦服务发生问题,如何保证数据不会丢失?
高可靠解决方案
MySQL用BinLog来解决这个问题,它把每一步事务操作都记录下来,一旦发生问题,可以追踪binlog找到每一步的操作记录。MySQL还会提供快照、备份的功能。
HDFS通过多副本和ZooKeeper的选举机制来解决这个问题,它会把收到的每一份数据存成N个副本,当发生故障的时候,通过ZooKeeper来确定最新的副本数据。另外,HDFS也提供快照SnapShot的功能。
storm里面是通过ack和Trident搞定。
Spark比较复杂,不同版本不一样,1.3之前是用Receiver保存offset,重启后先获取上一次的offset,然后到kafka重新读取数据。1.3之后,跟Flink一样用checkpoint机制存储任务所有元数据,包括offset。具体可以看我之前分析的这篇文章,点击查看:SparkStreaming实时任务处理的三种语义。
Flink的Checkpoint机制
MySQL的思想很容易理解,就像棋谱一样,把每一步都记录下来。后人读棋谱,可以随时切换到任意一张棋谱,然后跟着每一步的操作重现当时的情景。
HDFS的思想也比较好理解,怕丢数据,就存成N份。只要写进去最少副本数,就自动会把所有旧副本都覆盖了,最大程度的保存好数据。而且他们都属于离线数据库,随时可以存一个快照。
但是Flink不一样啊,MySQL和HDFS都是离线存储,Flink是在线的,是一个数据流呀,不能停啊!也不能把数据流做一个快照啊,那咋弄?
其实现实世界就有这种场景:

顾客源源不断的往收银台上的传送带上放物品,收银员负责扫码、计算、收钱。前面那个顾客和后面的顾客的东西都放在一起,怎么区分?你看Flink的场景跟超市购物是不是一样一样的?
最简单的方式是:
顾客1放商品到收银台
收银员把顾客1的东西陆续扫完,并结账
清台
顾客2放商品上去,重复步骤2、3
但是这样也太慢了点吧!这时间浪费的太多了!
于是就有了这个:下图中的“欢迎光临”:

在每个顾客之间,放一个“欢迎光临”,隔断一下就行了。“欢迎光临”之前的商品该扫码扫码,该结账结账。等看到“欢迎光临”了,就相当于看到Checkpoint的标志了,把小票数据上报系统。
在Flink中就是这样:
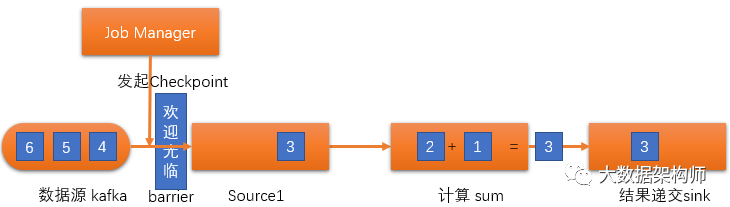
第1步:由Job Manager初始化Checkpoint,在数据源之后放一个barrier“欢迎光临”,以此为隔断。在“欢迎光临”下游的数据,照常处理。
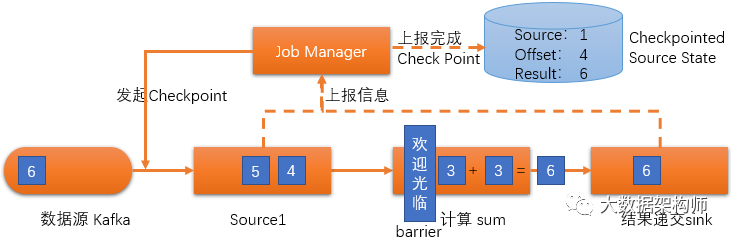
第二步:在“欢迎光临”下游的所有数据都处理完毕之后,我们就可以获取到几个信息:CheckPoint的source、数据源的offset和最终计算的Result。然后我们把这几个数据存到state里面就好了。这样就即能搞定Checkpoint的记录,又不耽误流式数据的处理了。一旦任务发生故障,重启任务,到State中读取所有任务元数据,重来一遍就好了。
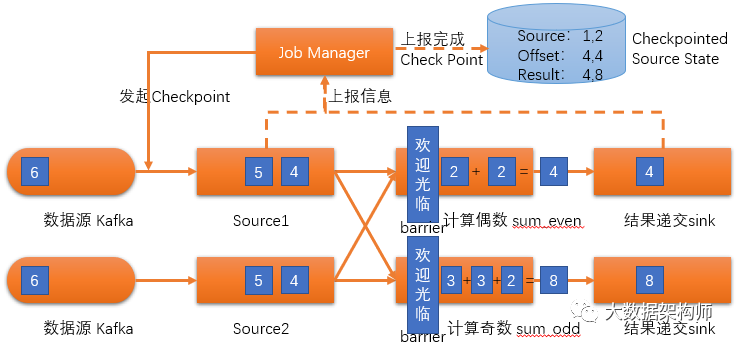
当然,上面只是并行度为1的情况,这两个图可以画的更复杂一些,并行度为2的情况,原理也是一样一样的:
第一步:发起Checkpoint:

第二步:将所有barrier下游的数据都计算完,并将source、offset等数据上报至State,存好。
当然,再复杂一些,就会遇到Checkpoint的时间过长的问题了。短时间内,Flink会把该barrier后的数据暂时缓存下来,等Checkpoint完成之后再进行计算。另外,还会启动Checkpoint超时时间,超过这么长时间没完成,该Checkpoint将被丢弃,保证Flink的通畅。
Checkpoint的参数配置
//默认checkpoint功能是disabled的,使用
StreamExecutionEnvironment.enableCheckpointing方法来设置开启
checkpointStreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1秒进行启动一个Checkpointing【设置checkpoint的周期,建议不要太短,否则前一个checkpoint未完成,后面的又要启动】
env.enableCheckpointing(1000);
// 设置数据消费语义为exactly-once严格一次 【数据消费语义:严格一次,默认且推荐】
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔,可以适当放大】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间,建议结合资源和占用情况,可以适当加大。时间短可能存在无法成功的情况】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行几个检查点,一般1个就够。
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
总结
无论是结构化数据库还是分布式数据库,无论是实时还是离线,数据的高可靠和高可用都是必须要解决的问题。单点故障就用主从、分布式解决,防止任务故障,就用各种log、快照、checkpoint解决。
一个新技术的出现,总是会遇到各种问题,但也同样会有高手来解决问题。我要赞美这些聪明的脑袋,是怎么想出这么奇妙的解决方案的?
配合以下文章享受更佳
干货 |SparkStreaming实时任务处理的三种语义
剖析 |MapReduce全流程【附调优指南】
干货 |ZooKeeper的ZAB、Watch详解
我需要你的点赞,爱你哟