哈喽,大家好,我是可乐
总结了一些常见的概率与统计类的数据分析面试题,不定期更新……
一、随机变量的含义
一个随机事件的所有可能的值X,且每个可能值X都有确定的概率P,X就是P(X)的随机变量。比如掷骰子中出现的点数
二、随机变量和随机试验间有什么关系
1、随机试验:相同条件下对某随机现象进行的大量重复观测的试验,如掷硬币100次统计正面朝上的次数
2、随机变量:是用来描述随机试验结果的。
三、划分连续型随机变量和离散型随机变量的依据
1、离散型随机变量:随机变量X能被一一列举出来,如一批产品中次品的数量,某地区人口的出生数等。
2、连续型随机变量:随机变量X不能被一一列举出来,如一批电子元器件的寿命,身高、体重等。
所以划分二者的依据是随机变量是否可数
四、变量独立和不相关的区别
若X和Y不相关,通常认为X和Y之间是没有线性关系,但不排除没有其他关系
若X和Y独立,是没有关系,互不干扰
因此,“不相关”是一个比“独立”要弱的概念
五、常见分布的分布函数/概率密度函数,以及分布的特性。
分别从离散型和连续型两方面说:
1、离散型随机变量的分布(1)二项分布进行一系列独立试验 -> 每一次试验都存在成功和失败的可能,且成功的概率相同 -> 试验次数有限。
二项分布记做X~B(n,p),X表示n次试验中的成功次数,我们要求的是成功的次数
(2)伯努利分布0-1分布,每次试验的结果只有2种,是n=1的二项分布的特殊情况
如掷硬币,只有正面朝上或反面朝上两种情况
(3)几何分布独立试验->拿到一种卡片的概率相同->为了集齐卡片要进行多少次试验
(4)泊松分布单独事件在给定区间内随机、独立地发生(给定区间可以是时间或空间) ->已知该区间内的事件平均发生次数,且为有限数值。
如某加油站,平均每小时来加油的车辆为10辆,泊松分布求的这个加油站每小时前来加油的车辆次数的概率
关于离散型随机变量分布可参考:

离散型随机变量的概率分布
2、连续型随机变量的分布(1)正态分布又叫高斯分布,正态分布通过参数平均值和方差确定
也叫矩形分布,概率密度函数的结果是一个固定的数值

均匀分布在自然情况下极为罕见,它的概率密度函数为:

image
(3)指数分布指数分布是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。如旅客进机场的时间间隔,还有许多电子产品的寿命分布一般服从指数分布。
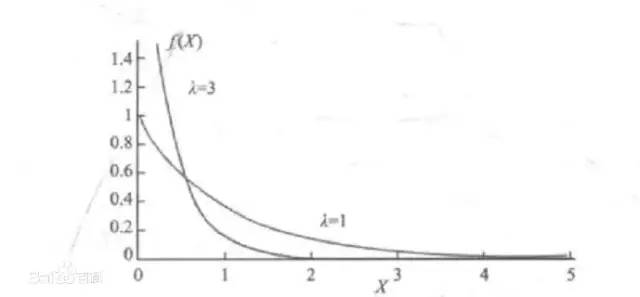
其概率密度函数为:

image
指数分布具有无记忆的关键性质。这表示如果一个随机变量呈指数分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少s+t小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
关于连续型随机变量的分布,可参考:

终于搞清楚正态分布、指数分布到底是啥了!
六、协方差和相关系数的区别1、协方差
只表示相关的方向
衡量两个变量的总体误差,方差是协方差的特殊情况,即当两个变量是相同的情况。
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值(你变大,我也变大,协方差就是正的)。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
也就是说,协方差为正,表示两个变量同变化,为负,不同变化
并且协方差的绝对值不反映线性相关的程度(其绝对值与变量的取值范围有关系)
但是嘞协方差为0的两个随机变量是不相关的
2、相关系数不仅表示线性相关的方向,还能衡量其相关程度
研究变量之间线性相关程度的量,取值范围是[-1,1]。
相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
七、中位数是否等于期望
标准正态分布中位数等于期望
右偏(正偏)态时,中位数小于期望
左偏(负偏)态时,中位数大于期望
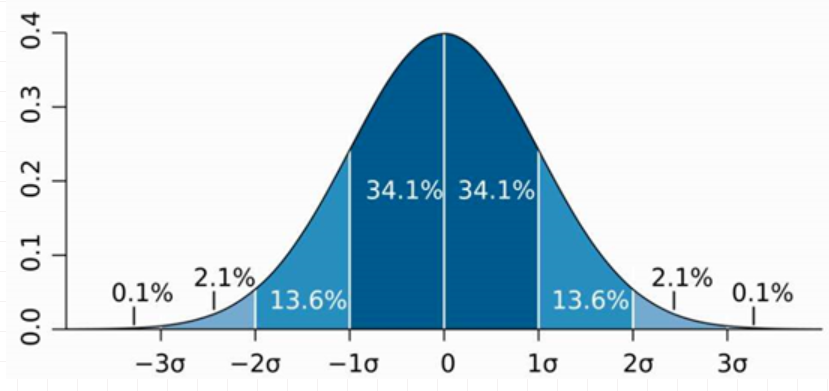
八、正态分布的基本特征是什么
正态分布又叫高斯分布,是一个钟形曲线,曲线对称,中央部分的概率密度最大,越往两边,概率密度越小。μ决定了曲线的中央位置,σ决定了曲线的分散性,σ越大,曲线越平缓,σ越小,曲线越陡峭。
很多实际问题都是符合正态分布的,如身高、体重等。正态分布在质量管理中也应用的非常广泛,“3σ原则”就是在正态分布的原理上建立的。
3σ原则是:
1、数值分布在(μ—σ,μ+σ)中的概率为0.6826
2、数值分布在(μ—2σ,μ+2σ)中的概率为0.9544
3、数值分布在(μ—3σ,μ+3σ)中的概率为0.9974
因此可以认为,Y 的取值几乎全部集中在(μ—3σ,μ+3σ)]区间内,超出这个范围的可能性仅占不到0.3%,这是一个小概率事件,通常在一次试验中是不会发生的,一旦发生就可以认为质量出现了异常。

image
九、什么是大数定律
在随机事件的大量重复出现中,往往呈现几乎必然的规律,这个规律就是大数定律。通俗地说,这个定理就是,在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。偶然中包含着某种必然。
在重复投掷一枚硬币的随机试验中,观测投掷了n次硬币中出现正面的次数。不同的n次试验,出现正面的频率可能不同,但当试验的次数n越来越大时,出现正面的频率将大体上逐渐接近于1/2。这就是大数定律。
十、什么是中心极限定理
假设一组随机变量相互独立且同分布,当n足够大时,均值的分布接近于正态分布
中心极限定理作用:
(1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体。
(2)根据总体的平均值和标准差,判断某个样本是否属于总体。
十一、假设检验的基本思想
小概率反证法。即为了检验一个假设是否成立,我们先假设它成立,在原假设成立的前提下,如果出现了不合理的事件,则说明样本与总体的差异是显著的,就拒绝原假设,如果没有出现不合理的事件,就不拒绝原假设。
这里所述的不合理的事件指的就是小概率事件,通常情况下我们认为一个小概率事件基本上不会发生,如果发生了,说明它就不是一个小概率事件了,所以要拒绝原假设。
十二、假设检验中的两类错误
第I类错误:弃真,原假设为真,却被我们拒绝了。
第II类错误:取伪,原假设为假,却没被拒绝。

十三、如何平衡这两类错误?
我们要尽可能地将犯两类错误的概率降到最低。但是,在样本容量固定的前提下,减少犯第I类错误的概率,必然会增加犯第II类错误的概率,一般来说,我们总是先控制犯第I类错误的概率,使它不大于显著性水平。而犯第II类错误的概率依赖于样本容量的大小,因此对样本容量的选择上,也要有所考量。
十四、解释P值
P值:当原假设为真时,样本观察结果或更极端的结果出现的概率就是P值
十五、区分显著性水平和置信区间
1、显著性水平:希望在样本结果的不可能程度达到多大时,就拒绝原假设,也就是小概率事件发生的概率。则是假设真值是多少,然后检验这个假设是否可能为真。
2、置信区间,目的是根据样本构造一个区间,然后希望这个区间可以把真值包含进去,但是并不知道这个真值是多少?
十六、什么是条件概率
P(A|B)=P(AB)/P(B),条件概率P(A|B) 指在事件B发生的条件下事件A发生的概率,P(AB)表示事件A和B同时发生的概率,P(B)是事件B发生的概率,其演化式可以得到:P(A|B)P(B)=P(B|A)P(A)
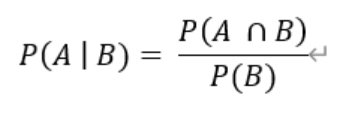
十七、全概率公式
假设事件B有两种发生方式,与事件A一起发生;不与事件A一起发生,那么可以用下面的公式得到事件B发生的概率:

又由条件概率可以推导出: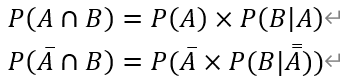
代入得到:
全概率公式
这就是全概率公式,由条件概率计算一个特定事件的概率。
十八、贝叶斯公式
假如已知的条件概率是P(B|A),那么贝叶斯公式则提供了一种计算逆条件概率的方法,也就是要求P(A|B)的概率。
首先条件概率:
刚刚也推导了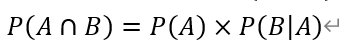
再将全概率公式P(B)代入,就得到:
贝叶斯公式
| 发现一个有趣的案例Q:一日某超市发生盗窃案,嫌疑人甲发生盗窃的可能性为10%,嫌疑人乙发生盗窃的可能性为90%,目击者称盗窃者是甲,目击者证言可信度为80%,那么现在请估算出目击者证言的准确度。
思路:嫌疑人甲盗窃的概率为P(A)=10%
嫌疑人乙盗窃的概率为P(B)=P(A)=90%
目击者证言可信度的概率为P(C)
在甲盗窃的前提下目击者称盗窃者是甲的概率为P(C|A)=80%
在甲盗窃的前提下目击者称盗窃者不是甲的概率为P(C|A)=20%
现在要求的是P(A|C)也就是目击者证言可信度准确的前提下甲盗窃的概率。
我们要求的是一个条件概率P(A|C),已知的一个条件概率P(C|A)刚好是要求的条件概率的逆概率,这里就要用到贝叶斯公式了。
P(A|C)=P(A)P(C|A)/(P(A)P(C|A)+P(A)P(C|A))
=10%80% / 10%80%+ 90%*20%
=30.77%
持续更新中......
-END-