编 辑:郑保卫
来 源:大数据架构师
01 城商行数据治理背景在所有行业中,电信、金融、电网、互联网领域数据治理的进度应该是最强的。其中金融行业的平均水平应该是最强的,因为监管力度太强了,不听话就得罚款。老彭之前分享过好多银行因“数据治理”不力而被罚几千万的案例了。
2021 年中国人民银行发布的《金融业数据能力建设指引》和 2018 年中国银保监会发布的《银行业金融机构数据治理指引》等都对银行数字化转型和数据治理能力提升提出更高、更新的要求。
上层要求加速推进全行级数据资产管理的实施落地,符合央行数据建设能力和银保监会数据治理指引要求,是金融市场主体和监管部门的数据共享能力、数据管理能力和综合分析能力建设的必要组成部分。
另外一个核心原因是金融是数字原生行业,数据要素的价值显而易见,并且也非常容易实现数据变现。
书中案例全面开展数据资产管理实现对全行级系统数据标准实施的有效管控,包括开展元数据的规范和统一管理,实现全行数据资产的分类和展现;打造数据质量问题发现、分析、跟踪和解决的闭环管理流程,实现元数据采集解析自动化,数据管理平台化、流程化等。
02 城商行数据治理三年规划数据治理是一项长期的工作,制定长期规划尤为重要。某大型城商行首先制定了三年数据治理规划。
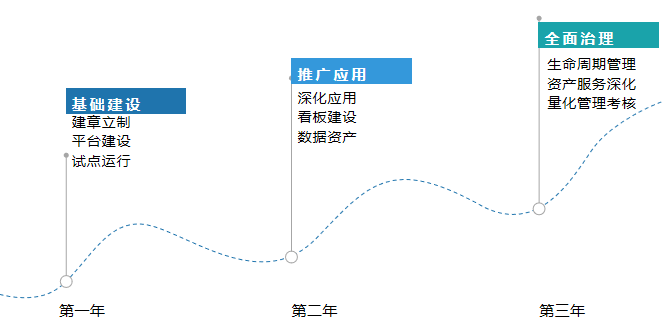
第一年,2020 年的工作重点为基础建设。主要包含以下三项内容。
● 建章立制:岗位职责完善、数据标准对标流程建设、元数据纳管体系建设、数据质量体系建设。
● 平台建设:建设可落地的数据治理平台,初步实现元数据纳管,支撑支持数据质量和数据标准管理功能。
● 试点运行:覆盖 20% 现有系统及当年新建所有系统数据字典纳管,规范数据字典变更申报流程并挑选 5 套关键业务系统进行试点,通过平台实现元数据纳管全流程。
第二年,2021 年工作重点为推广应用。主要包含以下三项内容。
● 深化应用:迭代优化元数据管控流程、数据标准管控流程、数据标准智能对标流程,扩大数据治理工作范围,超 100 套主要业务系统全部纳入数据治理范围。
● 看板建设:实现数据质量问题收集、数据质量问题分发、进度跟踪展示、数据质量问题定期监测评价,打造数据质量管控闭环。
● 数据资产:开启数据资产分类、盘点,实现元数据管理、展示、查询。
第三年,2022—2023 年核心为全面治理。主要包含以下 3 项内容。
● 生命周期管理:通过数据管理全面融入开发、业务管理流程实现全数据全生命周期管控。
● 资产服务深化:拓展资产服务内容,构建数据全景视图,使数据使用人员对数据资产情况一目了然,挖掘资产价值,开展资产运营。
● 量化管理考核:开展数据标准实施效果的监测、元数据管理准确度的分析和数据质量看板的进度监测等,实现数据治理工作成果可视化,对数据治理机构和人员进行评估、考核和排名。
03 实施路径结合三年的长期规划,制定实施路径,并按计划执行:
1)准备阶段分析梳理行内现状,厘清数据治理痛点及主要诉求,确认项目实施范围,确定数据治理组织架构。
2)第一阶段● 采集纳管系统元数据,梳理数据字典,实现线上化、流程化管控数据字典的变更。
● 修订覆盖业务系统、数仓、大数据平台的数据标准(包含业务标准及技术标准),并完成全量对标。
● 打通行内指标管理平台,统一管理全行指标。
● 以 EAST 监管报送为试点,完善数据治理检核规则,并线上化调度运行。
3)第二阶段● 推广数据字典、标准实施、数据质量流程应用,优化业务流程,迭代数据标准版本。
● 制定 SQL 脚本统一规范,解析系统、数仓、大数据平台内外血缘关系。
● 通过血缘关系实现指标溯源,完善血缘及影响分析。
4)第三阶段● 持续开展数据资产集中管理和科学分类,使平台接入的数据资产编目清晰、随时可查,拓展数据资产服务场景。
● 结合数据质量管理办法自动生成数据质量报告,并在质量看板系统中展示,实现各类数据质量日常监测。
● 数据全生命周期管理,实现平台与现有开发工具打通,元数据管控全面融入开发、业务管理流程。
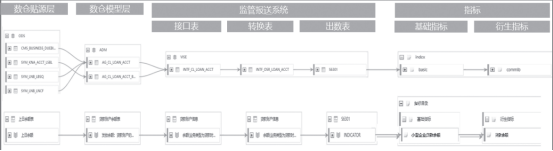
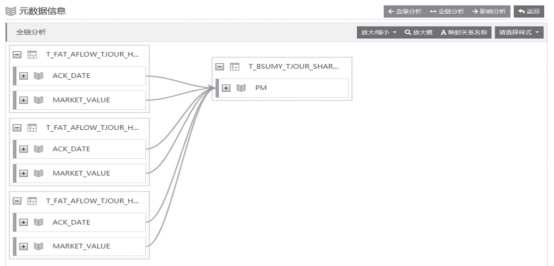
04 项目实战结果(1)实现全行级元数据管理实时监控元数据变化,构建动态数据地图,构建全行级信息系统元数据管理知识库。
一是定时采集、解析元数据,包括关系型数据库、数据仓库、大数据平台和报表平台以及 ETL 迁移、存储过程日志 SQL 解析等,展示表级、字段级元数据的血缘分析和影响分析。
二是调研现有的信息系统,分析各系统元数据内容,建立全行级信息系统元数据知识库,实现元数据全面采集、准确解析、全局展示的目标,将数据资产管理平台打造成为用户提供数据认知的服务型系统平台。
三是构建动态的数据地图,发挥数据地图的定位性、实时性、准确性、导航性等功效,为掌握数据资产的整体布局、来龙去脉、变化影响等内容提供有力支撑。
实现数据标准的线上化、流程化管理,提供数据标准的落标和智能对标。
一是搭建数据资产管理平台,实现数据标准管理,为用户提供数据标准查询功能,支持数据标准的申请、审核流程。数据标准管理内容包括业务标准、技术标准和指标标准。
二是基于自然语言形成的单词库,进行智能对标,自动建立系统数据字典与数据标准的映射关系,多种对标推荐模式(精确推荐、模糊推荐、自定义推荐等)进行数据标准精确推荐,准确率达到 90% 以上。
三是项目建设过程中,为数据仓库、大数据平台提供技术标准,开展数据标准的实施。
(3)实现数据字典流程化管控梳理业务系统数据字典,进行数据结构变更流程化管控。
一是梳理重点业务系统、数据仓库、数据集市的数据字典,通过对数据字典批量规则检核、人工补录的方式提升数据字典入库的质量,目前已纳管超 100 套系统。
二是平台上线后,对纳入管控的系统进行流程化管理,将数据字典变更流程嵌入开发流程,从需求分析到数据字典变更上线,进行全流程管理,实现入仓源系统数据字典及下游数据字典透明化管控。
三是定时检测生产、测试、开发等环境的数据字典,支持跨环境差异比对。
四是提供数据字典版本管理、变更影响度、差异比对和差异 DDL、数据字典变更自动生成 DDL 等功能,辅助项目经理进行数据字典管理。
五是提供数据字典差异排名、质量校验排名等统计分析可视化报表。
(4)实现数据质量与考核结合将数据质量与数据考核相结合,激励数据质量提升。
一是提供数据质量计划管理、解决方案管理、规则模板管理、规则管理、规则调度和问题分发等功能,保证问题从产生到解决的流程化管控,自动生成数据质量问题情况并在看板系统中展示,以此激励数据质量的提升。
二是实现数据质量全生命周期管控,提供灵活自定义规则功能,完善数据质量问题分发及问题解决跟踪流程及机制,逐步建立总行各部门及分行质量评价机制,实现针对数据质量问题及时发现、及时解决、效果可评价的目标。
三是目前已制定 1000+ 数据质量规则,规则主要围绕客户数据、账户数据、业务数据及监管关注重点数据。
(5)实现与流程管理系统对接与 IT 综合管理平台以及测试管理平台对接,实现数据字典变更和数据标准落地的强管控。
一是与 IT 综合管理平台流程相结合,在需求、开发及测试阶段管理数据字典和标准落标情况,新建系统上线需要在 IT 管理平台进行数据字典流程审批,审批通过后项目方可上线。
二是提供数据字典变更的影响分析和数据标准对标的智能推荐,提升数据字典管理的效率及效果。
05 实战经验总结(1)存量与增量字段全贯标,结合数据平台制定全面覆盖的技术标准综合考虑实施难度和成本,采取“存量对标、增量落标”的策略。一方面,存量系统清单式管理,根据对标结果在变更时实施强制落标。通过平台的智能对标功能智能实现存量系统字段全面对标,将数据标准与数据字典中的数据项建立映射关系。结合数据字典变更申报流程,在有新的表、字段增加或者修改时,对存量系统中的新增字段要求落标。另一方面,新建系统要求全面落标。在新建系统数据字典设计阶段,要求在平台申报、审核、对标,并出具数据标准实施意见,要求应落标字段全面落标。
通过存量、新增系统差异化的数据标准实施策略,一方面避免了由于存量字段过多、涉及系统范围过大,强制落标可能造成的风险,另一方面,达到了业务字段全贯标的要求,并且能促进全行级数据标准的迭代修订,使数据标准更契合业务实际。
在制定数据标准的过程中,秉承“权威主导、多方支持、用户参与”的原则,吸纳权威标准、制度文件、各类监管要求中的标准信息项,组织使用标准的部门共同参与梳理流程,制定切实可用的企业级数据标准。以大数据平台的标准层、模型层为切入点,逐渐将落标范围覆盖至数仓、业务系统及大数据平台。同时,通过与存量重点业务系统的对标,紧密结合业务实际,吸纳“事实标准”,实现业务反哺标准。
在修订业务标准时,细化颗粒度至单词、数据元级别。通过由单词构成标准的方式进一步规范标准中文名称的一致性,通过中文语义的词根和类型、长度进一步规范标准的技术属性。
(2)事前贯标、事中管控、事后差异比对,实现元数据全流程管控嵌入行内 IT 综合管理平台,管控项目全生命周期的各重要阶段。在需求阶段规范业务人员提出的数据项,并对其进行标准化。在设计阶段,提供标准引用及智能对标服务,确保高贯标率。在智能对标服务中,采用人工智能算法,基于自然语言分析技术和历史贯标结果的自主学习,为用户提供自动对标、精确推荐、模糊推荐等便捷的映射方法,极大地提高人工贯标的效率。另外,针对变更的表、字段,实时查询血缘及影响分析,支持数据管控前移。
在测试投产阶段,严控贯标后的执行情况。投产 DDL 脚本使用资产管理平台生成的脚本,并将生成的脚本直接发至可执行目录下,避免手动编写脚本,降低人为原因导致的投产风险。
投产完成后,再次采集生产环境元数据进行差异比对,事后监测是否按照落标要求投产,若有差异则通过邮件、短信、OA 系统推送等多种渠道发送预警信息。在全流程管控体系中,覆盖了各类业务系统以及大数据平台。对 db2、oracle、mysql、postgre 等关系型数据库及 cdh 中的 impala、hive、hbase、hdfs 等大数据组件,均完全适配。
(3)制定企业级 SQL 规范,自动解析血缘关系,实现基础数据、指标双溯源制定企业级的 SQL 编写规范,有效解决不同系统、不同厂商、不同环境间 SQL脚本风格和写法不一致的问题。资产管理平台通过对统一规范的 SQL 进行自动解析,获得各系统、环境之间及内部的血缘关系。血缘关系的时效性为 T+1,准确性达到95% 以上。主要价值如下:
提供更直观的宏观数据地图展示,实时掌握各系统、环境间的数据流向,为架构设计、数据分析应用、供数取数服务夯实基础;在各类需求导致的数据库结构变更流程中,在设计阶段提前分析表结构变更可能带来的影响和风险,真正做到事前管控,并在变更完成后通知到被影响的系统,要求排查及验证;打通报表平台,对全行指标的来源、计算口径做统一流程管理,并将报表的取数依据与血缘关系相结合,对报表数据的异常情况,能够迅速定位异常数据的来源,高效解决报表问题。
(4)数据质量规则在关系型数据库、大数据平台中双落地,数据质量闭环管理线上化针对不同的数据质量检核场景,检核规则在关系型数据库与大数据平台双落地。质量规则检核模块支持对接关系型数据库和大数据平台 impala,实现数据质量问题明细获取、问题数据总量统计监测等多类场景应用。目前已部署质量规则千余条,应用场景涵盖 EAST、客户信息质量、数据标准一致性等。
通过数据资产管理平台,将数据质量管理流程化、可视化。支持数据质量问题按责任部门或责任机构自动分发至对应责任人、责任角色,通过“流转”“回退”“分发” “解决”等操作,实现对问题数据处理环节的准确记录和跟踪监测。
数据资产管理平台通过统一调度,自动比对两次质量规则检核的结果差异,实时更新问题数据状态,汇总解决情况。根据质量检核管理办法,自动计算解决率、解决时效、问题占比等信息,自动生成数据质量报告并在看板系统展示,为后续质量问题量化考核、评估提供支撑。
为了推动各业务条线和分支机构积极配合解决问题数据,将数据质量的整改率、完成率等指标作为考核指标,与其绩效考核挂钩,大幅调动了各个业务条线及分支机构的积极性,问题数据的整改数量和效率得到了显著提升。
以上就是城商行数据治理实战经验全解松花酿酒下一句的全部内容了,希望大家喜欢。